
YOLO缺陷检测模型训练完整指南
目录
引言
欢迎来到YOLO缺陷检测模型训练的完整指南。本指南专为YOLO初学者设计,将带您从零开始,逐步掌握使用YOLO算法训练缺陷检测模型的全过程。
为什么选择YOLO进行缺陷检测?
在工业4.0时代,自动化质量检测已成为制造业的核心需求。传统的人工检测方法不仅效率低下,而且容易受到主观因素影响,难以保证检测的一致性和准确性。计算机视觉技术,特别是深度学习算法的发展,为工业缺陷检测提供了革命性的解决方案。
YOLO(You Only Look Once)算法作为目标检测领域的重要突破,具有以下显著优势:
实时性能卓越:YOLO算法能够在保证检测精度的同时,实现实时检测,这对于工业生产线上的在线质量控制至关重要。传统的两阶段检测算法如R-CNN系列虽然精度较高,但检测速度较慢,难以满足实时性要求。
端到端训练:YOLO采用端到端的训练方式,将目标检测问题转化为回归问题,简化了训练流程,降低了实现复杂度。这使得即使是初学者也能相对容易地上手使用。
统一框架设计:与需要多个步骤的传统方法不同,YOLO使用单一神经网络同时完成目标定位和分类任务,大大简化了系统架构。
适应性强:YOLO算法经过多年发展,已经演化出多个版本(YOLOv1到YOLOv11),每个版本都在精度和速度方面有所改进,能够适应不同的应用场景需求。
缺陷检测的挑战与机遇
工业缺陷检测面临着独特的挑战,这些挑战也为深度学习技术的应用提供了机遇:
小样本问题:在实际工业环境中,缺陷样本往往数量有限,这与深度学习通常需要大量训练数据的要求形成矛盾。然而,通过数据增强、迁移学习、半监督学习等技术,我们可以有效解决这一问题。
实时性要求:生产线上的质量检测需要在极短时间内完成,以避免影响生产效率。YOLO算法的高速检测能力正好满足这一需求。
多样化缺陷类型:不同行业、不同产品的缺陷类型差异很大,从钢材表面的划痕、斑块,到PCB板的短路、开路,再到纺织品的破洞、污渍。YOLO算法的灵活性使其能够适应各种缺陷检测任务。
环境复杂性:工业环境中的光照条件、背景噪声、产品姿态等因素都会影响检测效果。通过合理的数据预处理和模型优化,YOLO能够在复杂环境中保持稳定的检测性能。
本指南的特色
本指南具有以下特色,确保您能够从中获得最大收益:
循序渐进的学习路径:从基础概念开始,逐步深入到技术细节,确保没有深度学习基础的读者也能跟上学习进度。
理论与实践并重:不仅详细解释YOLO算法的理论原理,还提供完整的实践指导,包括代码示例和实际操作步骤。
丰富的数据集资源:精心整理了多个高质量的缺陷检测数据集,并提供详细的获取和使用指南。
实战案例驱动:以具体的缺陷检测项目为例,展示完整的开发流程,让您能够直接应用到实际工作中。
问题导向的解决方案:针对初学者在学习和实践过程中可能遇到的各种问题,提供详细的解决方案和调试技巧。
通过学习本指南,您将能够:
- 深入理解YOLO算法的工作原理和技术细节
- 掌握缺陷检测项目的完整开发流程
- 学会选择和处理适合的数据集
- 具备独立训练和优化YOLO模型的能力
- 了解如何将训练好的模型部署到实际生产环境中
让我们开始这段激动人心的学习之旅吧!
YOLO算法理论基础
从传统方法到深度学习的演进
在深入了解YOLO算法之前,我们需要理解目标检测技术的发展历程。这将帮助您更好地理解YOLO算法的创新之处和优势所在。
传统目标检测方法
早期的目标检测主要依赖于手工设计的特征提取器,如HOG(Histogram of Oriented Gradients)、SIFT(Scale-Invariant Feature Transform)等。这些方法通常包含以下步骤:
- 特征提取:使用预定义的算法从图像中提取特征
- 候选区域生成:通过滑动窗口等方法生成可能包含目标的区域
- 分类器训练:使用SVM等传统机器学习算法对提取的特征进行分类
- 后处理:通过非极大值抑制等方法去除重复检测
这种方法的主要问题在于:特征提取能力有限,难以处理复杂场景;计算效率低下,无法满足实时性要求;泛化能力差,需要针对不同任务重新设计特征。
深度学习时代的目标检测
深度学习的兴起彻底改变了计算机视觉领域。卷积神经网络(CNN)强大的特征学习能力使得目标检测的精度得到了显著提升。深度学习时代的目标检测算法主要分为两类:
两阶段检测算法(Two-Stage):
- 代表算法:R-CNN、Fast R-CNN、Faster R-CNN
- 工作流程:首先生成候选区域(Region Proposals),然后对每个候选区域进行分类和边界框回归
- 优势:检测精度高,特别适合对精度要求严格的应用
- 劣势:计算复杂度高,检测速度慢,难以实现实时检测
单阶段检测算法(One-Stage):
- 代表算法:YOLO系列、SSD、RetinaNet
- 工作流程:直接在特征图上预测目标的类别和位置,无需生成候选区域
- 优势:检测速度快,能够实现实时检测
- 劣势:早期版本在精度上略逊于两阶段算法
YOLO作为单阶段检测算法的开创者,在保证检测速度的同时,通过不断的算法改进,逐步缩小了与两阶段算法在精度上的差距。
YOLO算法的核心思想
YOLO算法的名称"You Only Look Once"完美诠释了其核心思想:只需要看一次图像,就能同时完成目标定位和分类任务。这种设计理念带来了革命性的改变。
问题重新定义
传统的目标检测方法将问题分解为两个子问题:目标定位和目标分类。而YOLO将整个目标检测问题重新定义为一个回归问题,直接从图像像素预测边界框坐标和类别概率。
这种重新定义带来了以下优势:
- 简化了网络结构:无需复杂的候选区域生成网络
- 提高了检测速度:避免了多次前向传播
- 增强了全局理解:网络能够看到整个图像的上下文信息
网格化处理策略
YOLO的核心创新在于将输入图像划分为S×S的网格(通常S=7或S=13),每个网格单元负责检测中心点落在该单元内的目标。这种设计有以下特点:
- 责任分工明确:每个网格单元只负责检测特定区域的目标,避免了重复检测
- 并行处理能力:所有网格单元可以并行处理,提高了计算效率
- 空间约束合理:通过网格划分,将全局检测问题分解为局部检测问题
统一的输出格式
YOLO为每个网格单元定义了统一的输出格式:每个单元预测B个边界框(通常B=2),每个边界框包含5个值(x, y, w, h, confidence),同时预测C个类别概率(C为数据集中的类别数量)。 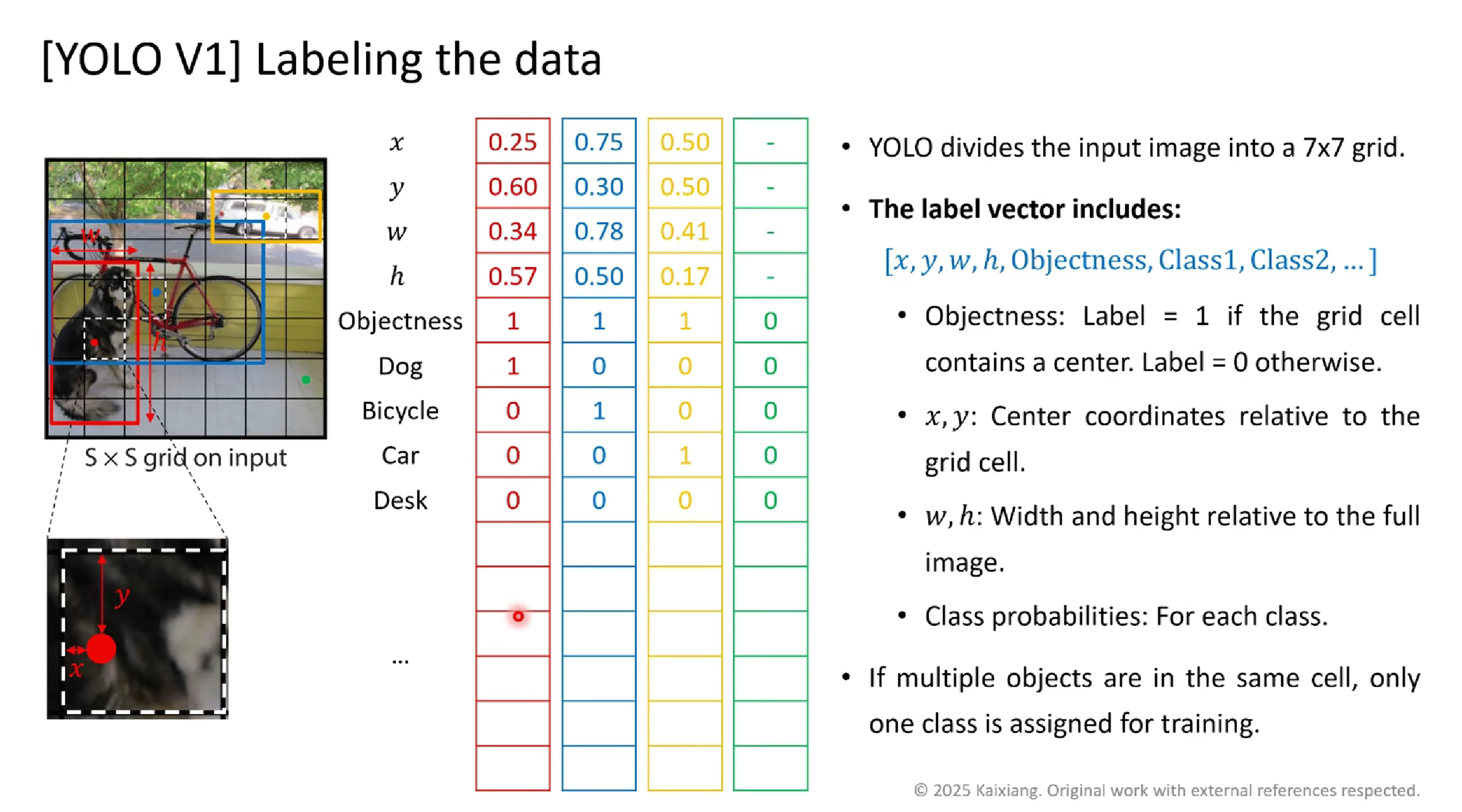 这种统一的输出格式使得:
这种统一的输出格式使得:
- 网络结构简洁:输出层的设计非常直观
- 损失函数统一:可以使用统一的损失函数进行端到端训练
- 后处理简单:输出结果可以直接用于最终的检测结果生成
YOLO算法的工作流程
理解YOLO的工作流程对于掌握其原理至关重要。整个流程可以分为以下几个关键步骤:
步骤1:图像预处理
输入图像首先被调整到固定尺寸(如448×448像素)。这种尺寸标准化是必要的,因为:
- 网络输入要求:CNN网络通常需要固定尺寸的输入
- 计算效率考虑:统一的输入尺寸有利于批处理
- 特征提取优化:合适的输入尺寸能够平衡检测精度和计算速度
步骤2:特征提取
预处理后的图像通过卷积神经网络进行特征提取。YOLO的骨干网络(Backbone)负责从原始图像中提取丰富的语义特征。这个过程包括:
- 多尺度特征提取:通过多层卷积和池化操作,网络能够提取不同尺度的特征
- 语义信息编码:深层特征包含丰富的语义信息,有助于目标分类
- 空间信息保留:通过合理的网络设计,保留足够的空间分辨率用于目标定位
步骤3:网格划分与预测
特征提取完成后,网络将特征图划分为S×S的网格,每个网格单元进行独立预测:
- 边界框预测:每个单元预测B个边界框的坐标和置信度
- 类别预测:每个单元预测C个类别的概率分布
- 置信度计算:置信度反映了边界框包含目标的概率以及定位的准确性
步骤4:后处理
网络的原始输出需要经过后处理才能得到最终的检测结果:
- 坐标转换:将网络输出的相对坐标转换为绝对坐标
- 置信度筛选:根据置信度阈值过滤低质量的检测结果
- 非极大值抑制:去除重复检测,保留最佳的检测结果
YOLO网络结构详解
YOLO的网络结构设计体现了其"简洁而有效"的设计哲学。让我们详细分析其网络架构:
骨干网络(Backbone)
YOLO的骨干网络负责特征提取,其设计借鉴了GoogLeNet的思想,但进行了简化:
- 卷积层设计:使用24个卷积层进行特征提取,每个卷积层后跟批归一化和激活函数
- 池化策略:通过最大池化层逐步降低特征图的空间分辨率
- 通道数变化:从输入的3个通道逐步增加到1024个通道,增强特征表达能力
检测头(Detection Head)
检测头负责将提取的特征转换为检测结果:
- 全连接层:使用2个全连接层将卷积特征映射到最终的预测结果
- 输出维度:对于PASCAL VOC数据集(20个类别),输出维度为7×7×30
- 激活函数:使用Leaky ReLU激活函数,相比ReLU能够缓解梯度消失问题
网络参数分析
以YOLO v1为例,网络的关键参数包括:
- 网格数量:S = 7,将图像划分为7×7 = 49个网格单元
- 边界框数量:B = 2,每个网格单元预测2个边界框
- 类别数量:C = 20(PASCAL VOC)或C = 80(COCO)
- 输出维度:S × S × (B × 5 + C) = 7 × 7 × 30
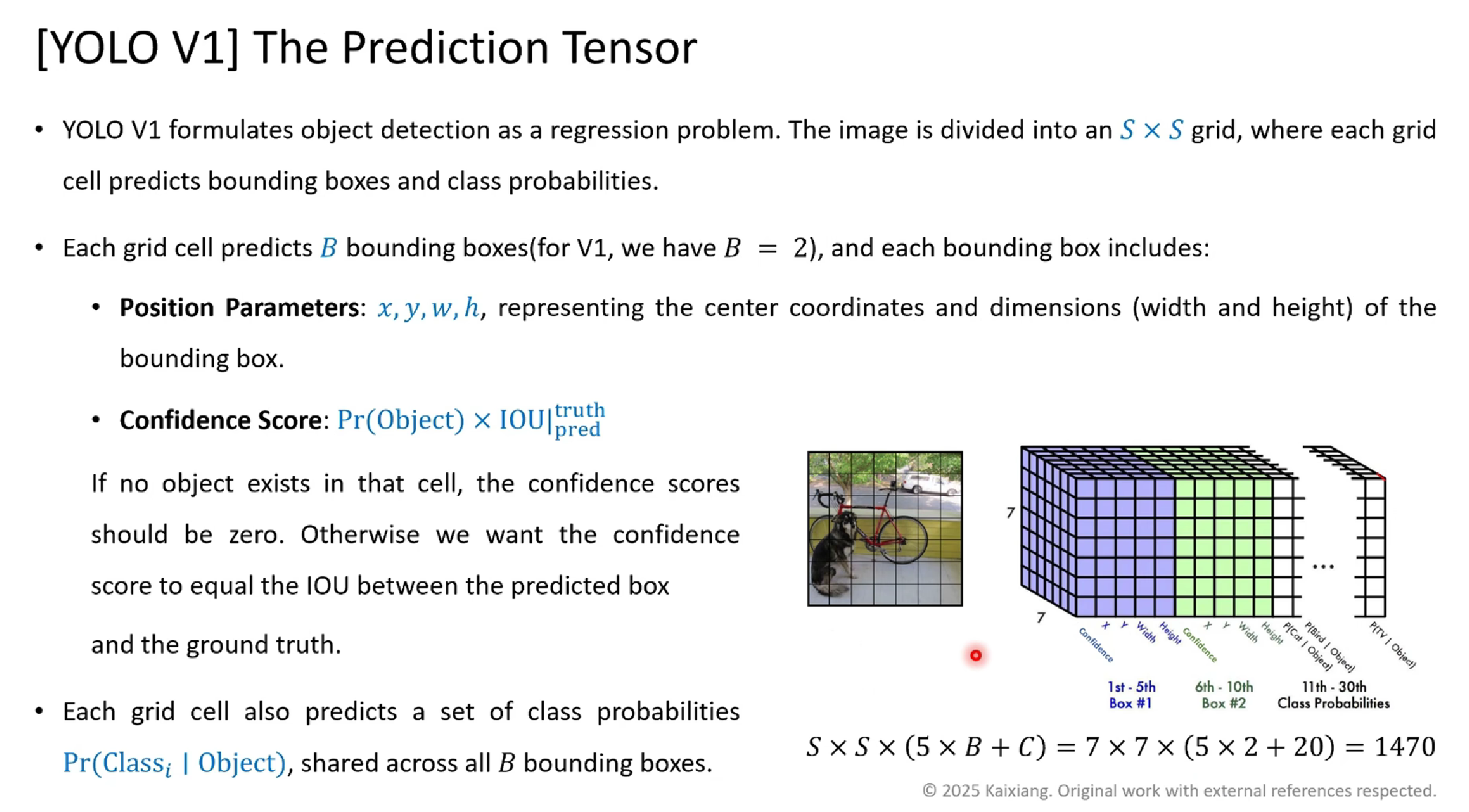 这种参数设置在检测精度和计算效率之间取得了良好的平衡。
这种参数设置在检测精度和计算效率之间取得了良好的平衡。
损失函数设计
YOLO的损失函数设计是其成功的关键因素之一。损失函数需要同时考虑定位精度和分类精度,并且要处理正负样本不平衡的问题。
多任务损失函数
YOLO的损失函数包含三个主要组成部分:
- 坐标回归损失:用于优化边界框的位置预测
- 置信度损失:用于优化目标存在性的预测
- 分类损失:用于优化目标类别的预测
权重平衡策略
为了解决不同任务之间的重要性平衡问题,YOLO引入了权重系数:
- λcoord = 5:增加坐标回归损失的权重,提高定位精度
- λnoobj = 0.5:降低负样本置信度损失的权重,缓解正负样本不平衡
尺度敏感性处理
对于不同尺寸的目标,相同的坐标偏差会产生不同的影响。YOLO通过对宽度和高度取平方根来缓解这个问题:
- 大目标:平方根操作降低了大目标尺寸预测误差的影响
- 小目标:相对提高了小目标尺寸预测误差的重要性
这种设计使得网络对不同尺寸的目标都能保持较好的检测性能。
深度学习与目标检测基础
深度学习基础概念
对于没有深度学习基础的读者,理解一些基本概念是掌握YOLO算法的前提。让我们从最基础的概念开始。
人工神经网络的灵感来源
人工神经网络的设计灵感来源于生物神经系统。在生物大脑中,神经元通过突触连接,接收输入信号,经过处理后产生输出信号。人工神经网络模拟了这一过程:
- 神经元(节点):接收多个输入,经过加权求和和激活函数处理后产生输出
- 连接权重:决定输入信号的重要性,通过学习过程不断调整
- 激活函数:引入非线性,使网络能够学习复杂的模式
- 层次结构:多个神经元组成层,多个层组成网络
深度学习的"深度"含义
深度学习中的"深度"指的是网络的层数。与传统的浅层网络相比,深层网络具有以下优势:
- 分层特征学习:浅层学习简单特征(如边缘、纹理),深层学习复杂特征(如形状、对象)
- 表达能力强:深层网络能够表达更复杂的函数映射关系
- 自动特征提取:无需人工设计特征,网络自动学习最优特征表示
卷积神经网络(CNN)的优势
对于图像处理任务,卷积神经网络是最适合的架构:
局部连接性:与全连接网络不同,CNN中的神经元只与局部区域连接,这符合图像的局部相关性特点。例如,一个像素点通常与其邻近像素点关系更密切。
权重共享:同一个卷积核在整个图像上共享权重,这大大减少了参数数量,同时使网络具有平移不变性。这意味着无论目标出现在图像的哪个位置,网络都能识别它。
层次化特征提取:CNN通过多层卷积和池化操作,逐步提取从低级到高级的特征:
- 第一层:检测边缘、线条等基本特征
- 中间层:组合基本特征形成更复杂的模式
- 深层:识别具体的对象和语义信息
目标检测任务的定义
目标检测是计算机视觉中的一个核心任务,它要求算法能够在图像中找到感兴趣的目标,并确定其位置和类别。
目标检测 vs 图像分类
理解目标检测与图像分类的区别对于初学者很重要:
图像分类:
- 任务目标:判断整张图像属于哪个类别
- 输出形式:类别标签和对应的概率
- 应用场景:图像标签、内容过滤等
- 技术难点:特征提取、分类器设计
目标检测:
- 任务目标:找到图像中所有感兴趣的目标,确定其位置和类别
- 输出形式:边界框坐标 + 类别标签 + 置信度
- 应用场景:自动驾驶、安防监控、工业检测等
- 技术难点:目标定位、多目标处理、尺度变化
目标检测的挑战
目标检测面临着比图像分类更多的挑战:
尺度变化:同一类目标可能以不同的尺寸出现在图像中。例如,在缺陷检测中,同样的划痕可能因为拍摄距离不同而呈现不同的尺寸。
遮挡问题:目标可能被其他物体部分遮挡,算法需要能够从部分信息推断出完整的目标。
背景复杂:工业环境中的背景往往复杂多变,算法需要能够区分目标和背景。
多目标检测:一张图像中可能包含多个目标,算法需要能够同时检测所有目标。
实时性要求:许多应用场景要求算法能够实时处理,这对算法的效率提出了很高要求。
评估指标详解
理解目标检测的评估指标对于模型训练和优化至关重要。
IoU(Intersection over Union)
IoU是目标检测中最基础的评估指标,用于衡量预测边界框与真实边界框的重叠程度:
IoU = (预测框 ∩ 真实框) / (预测框 ∪ 真实框)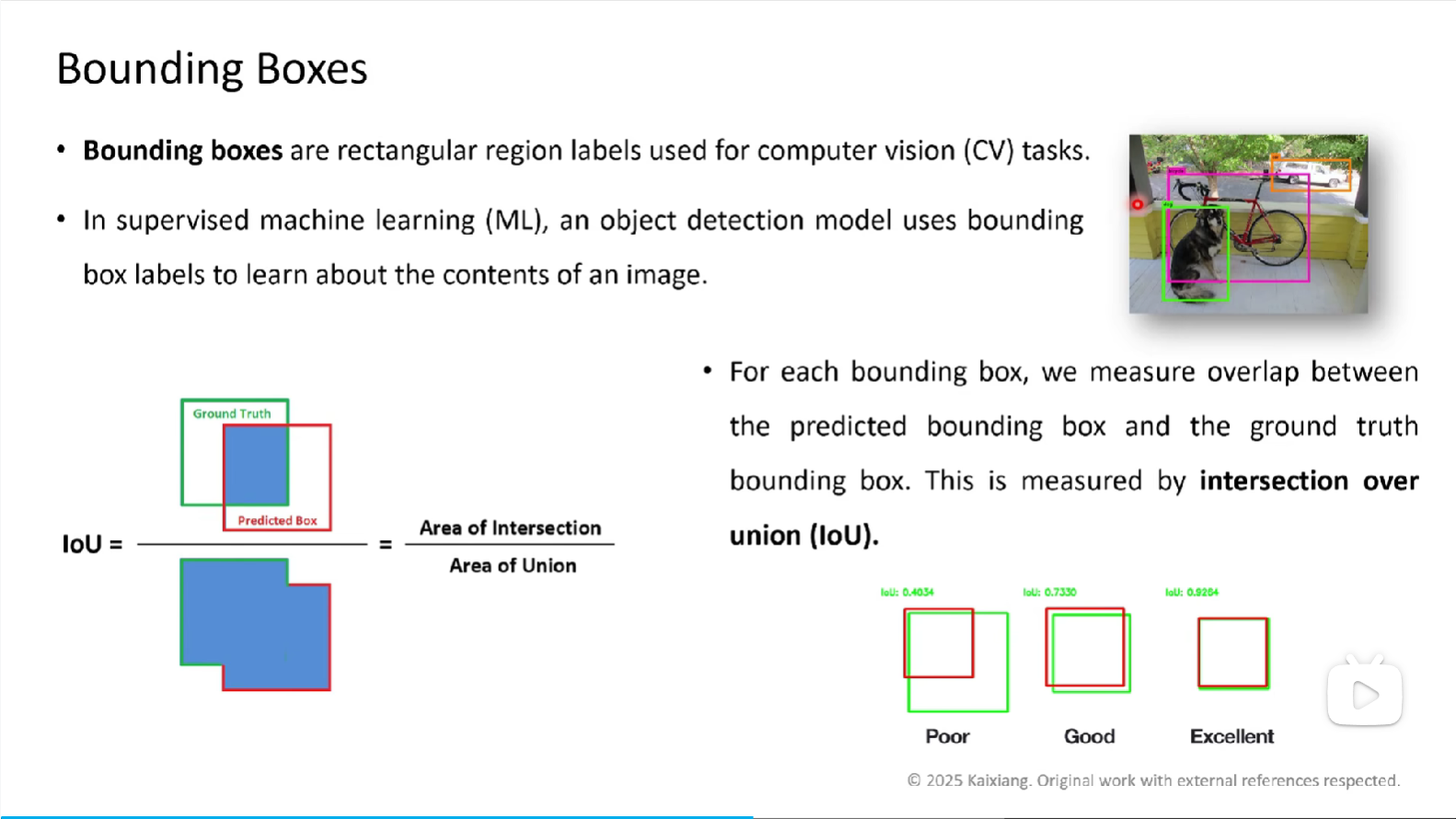 IoU的取值范围是[0, 1]:
IoU的取值范围是[0, 1]:
- IoU = 0:预测框与真实框完全不重叠
- IoU = 1:预测框与真实框完全重合
- IoU ≥ 0.5:通常认为是一个有效的检测结果
精确率(Precision)和召回率(Recall)
这两个指标来源于信息检索领域,在目标检测中有特殊的含义:
精确率:在所有预测为正例的样本中,真正为正例的比例
Precision = TP / (TP + FP)召回率:在所有真正为正例的样本中,被正确预测为正例的比例
Recall = TP / (TP + FN)其中:
- TP(True Positive):正确检测到的目标数量
- FP(False Positive):错误检测的目标数量(误检)
- FN(False Negative):漏检的目标数量
mAP(mean Average Precision)
mAP是目标检测中最重要的综合评估指标:
- 计算每个类别的AP:对于每个类别,绘制Precision-Recall曲线,计算曲线下面积
- 计算平均AP:将所有类别的AP取平均值得到mAP
mAP的变种:
- mAP@0.5:IoU阈值为0.5时的mAP
- mAP@0.5:0.95:IoU阈值从0.5到0.95(步长0.05)的平均mAP
数据标注与格式
目标检测需要高质量的标注数据,理解数据格式对于后续的模型训练至关重要。
边界框标注
目标检测中最常用的标注方式是边界框(Bounding Box),通常有两种表示方法:
方法1:左上角坐标 + 宽高
(x_min, y_min, width, height)方法2:左上角 + 右下角坐标
(x_min, y_min, x_max, y_max)常见数据格式
不同的框架和数据集使用不同的标注格式:
PASCAL VOC格式:
- 使用XML文件存储标注信息
- 坐标采用绝对像素值
- 包含详细的元数据信息
COCO格式:
- 使用JSON文件存储标注信息
- 支持多种标注类型(边界框、分割、关键点)
- 坐标采用绝对像素值
YOLO格式:
- 使用TXT文件存储标注信息
- 坐标采用相对值(0-1之间)
- 格式简洁,便于处理
标注质量的重要性
高质量的标注数据是训练成功模型的基础:
一致性:标注标准要保持一致,避免同一类缺陷在不同图像中标注方式不同。
完整性:确保所有目标都被正确标注,避免漏标。
准确性:边界框要尽可能准确地框住目标,避免过大或过小。
平衡性:各类别的样本数量要相对平衡,避免某些类别样本过少。
数据增强技术
由于缺陷检测往往面临小样本问题,数据增强技术显得尤为重要。
几何变换
几何变换是最常用的数据增强方法:
旋转(Rotation):随机旋转图像,增加模型对目标方向的鲁棒性。对于缺陷检测,这特别有用,因为缺陷可能以任意角度出现。
翻转(Flip):水平或垂直翻转图像,增加数据的多样性。
缩放(Scale):随机缩放图像,模拟不同的拍摄距离。
平移(Translation):随机平移图像,增加目标位置的多样性。
颜色空间变换
颜色空间变换可以增加模型对光照条件的鲁棒性:
亮度调整:随机调整图像亮度,模拟不同的光照条件。
对比度调整:随机调整图像对比度,增强模型的适应性。
色调调整:随机调整图像色调,增加颜色的多样性。
噪声添加:添加随机噪声,提高模型的抗噪能力。
高级数据增强技术
Mixup:将两张图像按一定比例混合,同时混合对应的标签。
CutMix:将一张图像的一部分替换为另一张图像的对应部分。
Mosaic:将四张图像拼接成一张图像,这是YOLOv4引入的技术。
这些高级技术能够进一步提高模型的泛化能力和鲁棒性。
YOLO算法详解
YOLO系列算法演进
YOLO算法自2015年首次提出以来,经历了多次重要的改进和升级。每个版本都在前一版本的基础上解决了特定的问题,并引入了新的技术创新。理解这一演进过程有助于我们更好地选择适合特定应用场景的YOLO版本。
YOLOv1(2015年):开创性的单阶段检测
YOLOv1是目标检测领域的一个重要里程碑,它首次提出了将目标检测作为回归问题来解决的思想。
核心创新:
- 统一检测框架:将目标检测问题重新定义为单一的回归问题
- 全局上下文信息:网络能够看到整个图像,避免了背景误检
- 实时检测能力:在当时的硬件条件下实现了实时检测
技术特点:
- 网格划分:将图像划分为7×7的网格
- 边界框预测:每个网格单元预测2个边界框
- 类别预测:每个网格单元预测一组类别概率
- 损失函数:多任务损失函数,同时优化定位和分类
主要局限:
- 小目标检测能力弱:由于网格划分较粗,难以检测小目标
- 密集目标处理困难:每个网格只能预测一个类别
- 定位精度有限:边界框回归精度不够高
YOLOv2/YOLO9000(2016年):精度与速度的平衡
YOLOv2在保持YOLOv1速度优势的同时,显著提升了检测精度。
主要改进:
Batch Normalization:在所有卷积层后添加批归一化,提高了训练稳定性和收敛速度,同时起到了正则化的作用。
高分辨率分类器:先在ImageNet上用448×448的高分辨率图像训练分类器,然后再进行检测任务的微调,提高了小目标的检测能力。
卷积锚框:借鉴Faster R-CNN的思想,引入锚框(Anchor Box)机制,每个网格单元可以预测多个不同尺寸和长宽比的目标。
维度聚类:使用K-means聚类算法在训练数据上自动选择锚框的尺寸,而不是手工设计。
细粒度特征:通过passthrough层将高分辨率特征与低分辨率特征结合,提高小目标检测能力。
多尺度训练:训练时随机改变输入图像尺寸,提高模型对不同尺寸目标的适应性。
性能提升:
- 精度提升:在PASCAL VOC 2007上的mAP从YOLOv1的63.4%提升到78.6%
- 速度保持:仍然能够实现实时检测
YOLOv3(2018年):多尺度检测的突破
YOLOv3引入了多尺度检测机制,显著提升了对不同尺寸目标的检测能力。
关键创新:
多尺度预测:在三个不同尺度的特征图上进行预测,分别适用于大、中、小目标的检测:
- 13×13特征图:检测大目标
- 26×26特征图:检测中等目标
- 52×52特征图:检测小目标
特征金字塔网络(FPN):采用类似FPN的结构,通过上采样和特征融合,充分利用不同层次的特征信息。
Darknet-53骨干网络:设计了新的骨干网络Darknet-53,具有更强的特征提取能力:
- 残差连接:借鉴ResNet的思想,解决深层网络的梯度消失问题
- 更深的网络:53层的网络结构,提供更强的表达能力
- 高效的设计:在保证精度的同时,维持较高的推理速度
逻辑回归分类:将softmax分类改为逻辑回归,支持多标签分类,适用于某些目标可能属于多个类别的场景。
性能表现:
- 精度显著提升:在COCO数据集上的性能大幅提升
- 小目标检测改善:多尺度检测机制显著改善了小目标的检测效果
- 速度仍然优秀:保持了YOLO系列的速度优势
YOLOv4(2020年):工程优化的集大成者
YOLOv4被称为"工程优化的集大成者",它集成了大量的训练技巧和网络改进,在精度和速度之间取得了新的平衡。
主要贡献:
CSPDarknet53骨干网络:采用CSP(Cross Stage Partial)结构,减少计算量的同时保持精度:
- 梯度流优化:改善梯度流动,提高训练效率
- 内存使用优化:减少内存占用,支持更大的batch size
- 推理速度提升:在保证精度的前提下提高推理速度
SPP(Spatial Pyramid Pooling):在骨干网络后添加SPP模块,增加感受野,提高特征表达能力。
PANet路径聚合:采用PANet的路径聚合结构,进一步改善特征融合效果。
数据增强技术:
- Mosaic数据增强:将四张图像拼接成一张,增加小目标的检测能力
- CutMix:随机裁剪和混合图像,提高模型鲁棒性
- DropBlock:结构化的dropout,提高正则化效果
训练策略优化:
- 余弦退火学习率:改善训练收敛性
- 标签平滑:减少过拟合,提高泛化能力
- 混合精度训练:加速训练过程
性能突破:
- COCO数据集:AP达到43.5%,超越了当时的EfficientDet
- 推理速度:在Tesla V100上达到65 FPS
- 实用性强:在精度和速度之间取得了很好的平衡
YOLOv5(2020年):工程化的典范
YOLOv5虽然在命名上存在争议,但其在工程化方面的贡献不可忽视。
工程化特色:
- PyTorch实现:基于PyTorch框架,代码结构清晰,易于理解和修改
- 自动锚框优化:自动分析数据集并优化锚框设置
- 模型缩放:提供不同尺寸的模型(YOLOv5s/m/l/x),适应不同的应用需求
- 部署友好:支持多种部署格式(ONNX、TensorRT、CoreML等)
技术改进:
- Focus结构:在网络开始部分使用Focus结构,减少计算量
- CSP结构优化:进一步优化CSP结构,提高效率
- 自适应训练:自动调整训练参数,降低使用门槛
YOLOv8(2023年):最新的技术集成
YOLOv8是Ultralytics公司推出的最新版本,代表了当前YOLO技术的最高水平。
架构创新:
- Anchor-Free设计:完全摒弃锚框机制,简化网络结构
- 新的骨干网络:设计了更高效的骨干网络结构
- 解耦检测头:将分类和回归任务分离,提高检测精度
训练优化:
- 改进的损失函数:使用更先进的损失函数设计
- 数据增强策略:集成最新的数据增强技术
- 超参数优化:自动化的超参数搜索和优化
多任务支持:
- 目标检测:传统的目标检测任务
- 实例分割:像素级的目标分割
- 图像分类:支持图像分类任务
- 姿态估计:人体关键点检测
YOLO核心技术深度解析
锚框机制的演进
锚框(Anchor Box)是目标检测中的重要概念,YOLO系列在这方面经历了重要的演进:
YOLOv1时代:没有锚框概念,直接预测边界框坐标,这导致了定位精度的限制。
YOLOv2引入锚框:借鉴Faster R-CNN的思想,为每个网格单元预设多个不同尺寸和长宽比的锚框。这种设计的优势包括:
- 提高召回率:多个锚框增加了检测到目标的可能性
- 改善定位精度:锚框提供了更好的初始化
- 处理多尺度目标:不同尺寸的锚框适应不同大小的目标
锚框优化策略:
- K-means聚类:在训练数据上使用聚类算法自动确定锚框尺寸
- 多尺度锚框:在不同尺度的特征图上使用不同大小的锚框
- 长宽比设计:根据数据集特点设计合适的长宽比
Anchor-Free的趋势:YOLOv8等最新版本开始采用无锚框设计,直接预测目标中心点和尺寸,简化了网络结构。
特征融合技术
特征融合是提高检测精度的关键技术,YOLO系列在这方面不断创新:
FPN(Feature Pyramid Network):
- 自顶向下路径:将高层语义信息传递到低层
- 横向连接:融合不同层次的特征
- 多尺度预测:在不同尺度的特征图上进行预测
PANet(Path Aggregation Network):
- 自底向上路径增强:在FPN基础上增加自底向上的路径
- 自适应特征池化:改善特征池化策略
- 全连接融合:增强不同层次特征的连接
BiFPN(Bidirectional Feature Pyramid Network):
- 双向特征融合:同时进行自顶向下和自底向上的特征融合
- 加权特征融合:为不同来源的特征分配不同权重
- 高效的网络设计:在保证效果的同时减少计算量
损失函数的演进
损失函数的设计直接影响模型的训练效果,YOLO系列在这方面也有重要发展:
YOLOv1的多任务损失:
Loss = λcoord × 坐标损失 + 置信度损失 + λnoobj × 负样本置信度损失 + 分类损失 改进的IoU损失:
改进的IoU损失:
- GIoU Loss:考虑预测框和真实框的最小外接矩形
- DIoU Loss:考虑两个框中心点的距离
- CIoU Loss:同时考虑重叠面积、中心点距离和长宽比
Focal Loss:解决正负样本不平衡问题,让模型更关注难分类的样本。
标签分配策略:
- 静态分配:基于IoU阈值的固定分配策略
- 动态分配:根据训练过程动态调整标签分配
- 最优传输分配:使用最优传输理论进行标签分配
缺陷检测中的YOLO应用特点
缺陷检测的特殊性
缺陷检测作为YOLO的重要应用领域,具有一些特殊的特点和挑战:
数据特点:
- 样本不平衡:正常样本远多于缺陷样本
- 缺陷多样性:同一类缺陷可能表现出不同的形态
- 尺度变化大:缺陷大小可能相差很大
- 背景复杂:工业环境中的背景往往复杂多变
检测要求:
- 高召回率:不能漏检缺陷,否则可能导致质量问题
- 低误检率:减少误检,避免不必要的成本
- 实时性:生产线上需要实时检测
- 稳定性:在不同环境条件下保持稳定性能
针对性优化策略
数据增强策略:
- 几何变换:旋转、翻转、缩放等,增加缺陷的多样性
- 颜色变换:调整亮度、对比度等,适应不同光照条件
- 噪声添加:增加模型的鲁棒性
- 缺陷合成:将缺陷区域合成到正常图像上
网络结构优化:
- 多尺度检测:使用多个尺度的特征图检测不同大小的缺陷
- 注意力机制:引入注意力机制,让模型更关注缺陷区域
- 轻量化设计:在保证精度的前提下减少计算量
训练策略优化:
- 迁移学习:使用预训练模型,减少训练时间
- 课程学习:从简单样本开始,逐步增加难度
- 对抗训练:提高模型的鲁棒性
- 知识蒸馏:使用大模型指导小模型训练
后处理优化:
- NMS优化:使用Soft-NMS等改进的非极大值抑制方法
- 置信度校准:校准模型输出的置信度
- 多模型融合:结合多个模型的预测结果
缺陷检测应用场景
工业缺陷检测的重要性
在现代制造业中,产品质量控制是确保企业竞争力和客户满意度的关键因素。传统的人工质检方法存在诸多局限性,而基于深度学习的自动化缺陷检测技术正在革命性地改变这一领域。
传统质检方法的局限性
主观性强:人工检测容易受到检测员的经验、疲劳程度、情绪状态等主观因素影响,导致检测结果不一致。
效率低下:人工检测速度有限,难以满足现代生产线的高速度要求,成为生产效率的瓶颈。
成本高昂:需要大量训练有素的检测人员,人力成本不断上升,特别是在劳动力短缺的地区。
漏检风险:人眼容易疲劳,对于微小缺陷或者在复杂背景下的缺陷,漏检率较高。
一致性差:不同检测员之间的标准可能存在差异,同一检测员在不同时间的判断也可能不一致。
自动化缺陷检测的优势
客观性强:基于算法的检测结果客观一致,不受主观因素影响。
高效快速:能够实现实时检测,满足高速生产线的需求。
成本效益:一次投入,长期使用,随着技术成熟,成本效益越来越明显。
精度可控:通过算法优化,可以达到甚至超越人眼的检测精度。
数据积累:检测过程中积累的数据可以用于质量分析和工艺改进。
主要应用领域详解
钢铁冶金行业
钢铁行业是缺陷检测技术应用最早、最成熟的领域之一。钢材表面缺陷检测对于保证产品质量和安全性至关重要。
常见缺陷类型:
- 轧制氧化皮(Rolled-in Scale):在轧制过程中氧化皮被压入钢材表面形成的缺陷
- 划痕(Scratches):由于机械摩擦或操作不当造成的表面划伤
- 斑块(Patches):表面不均匀的斑点状缺陷
- 裂纹(Cracks):材料内部应力导致的表面裂纹
- 麻点(Pitted Surface):表面的点状凹陷缺陷
- 夹杂物(Inclusion):钢材中的非金属夹杂物在表面的显现
检测挑战:
- 高温环境:钢材生产过程中的高温环境对检测设备提出了特殊要求
- 表面反光:金属表面的反光特性影响图像质量
- 生产速度快:钢材生产线速度很快,要求检测系统具有极高的实时性
- 缺陷多样性:同一类缺陷可能在不同条件下呈现不同的外观
技术解决方案:
- 多光源照明:使用多角度、多光谱的照明系统,减少反光影响
- 高速相机:采用高速工业相机,确保在高速生产条件下获得清晰图像
- 实时处理:使用GPU加速的YOLO算法,实现毫秒级的检测响应
- 自适应阈值:根据生产条件自动调整检测参数
电子制造业
电子制造业对产品质量的要求极高,微小的缺陷都可能导致产品功能失效。PCB(印刷电路板)缺陷检测是这一领域的典型应用。
PCB缺陷类型:
- 开路(Open Circuit):电路连接断开,导致信号无法传输
- 短路(Short Circuit):不应连接的电路之间形成连接
- 缺失孔(Missing Hole):应该有孔的位置没有孔
- 鼠咬(Mouse Bite):边缘不规则的锯齿状缺陷
- 杂散铜(Spurious Copper):不应该存在的铜箔残留
- 杂散(Spur):多余的金属突起
检测特点:
- 精度要求高:PCB上的线路非常精细,要求检测精度达到微米级
- 缺陷尺寸小:许多缺陷的尺寸很小,对算法的敏感性要求很高
- 背景复杂:PCB表面有复杂的电路图案,增加了检测难度
- 多层结构:现代PCB往往是多层结构,增加了检测的复杂性
技术要点:
- 高分辨率成像:使用高分辨率相机和精密光学系统
- 多尺度检测:YOLO的多尺度检测能力特别适合PCB缺陷检测
- 精确标注:需要非常精确的数据标注,确保训练数据的质量
- 实时反馈:检测结果需要实时反馈给生产系统
纺织服装业
纺织品缺陷检测是另一个重要的应用领域,涉及面料生产和成品检验等多个环节。
纺织品缺陷类型:
- 破洞(Holes):面料上的孔洞缺陷
- 污渍(Stains):各种污染造成的污渍
- 色差(Color Variation):颜色不均匀或色彩偏差
- 纬斜(Weft Skew):纬线倾斜造成的图案变形
- 断经(Broken Warp):经线断裂造成的缺陷
- 油污(Oil Stains):生产过程中的油污染
检测挑战:
- 纹理复杂:纺织品具有复杂的纹理结构,增加了缺陷识别的难度
- 柔性材料:纺织品是柔性材料,容易产生褶皱和变形
- 颜色多样:不同颜色和图案的面料需要不同的检测策略
- 生产速度快:现代纺织生产线速度很快,要求实时检测
汽车制造业
汽车制造对质量要求极高,缺陷检测涉及车身、零部件、涂装等多个方面。
汽车缺陷类型:
- 车身凹陷:冲压或装配过程中产生的凹陷
- 涂装缺陷:喷漆过程中的流挂、橘皮、色差等问题
- 焊接缺陷:焊缝不良、焊接飞溅等问题
- 装配缺陷:零部件装配不当或缺失
食品包装业
食品安全直接关系到消费者健康,包装缺陷检测是食品质量控制的重要环节。
包装缺陷类型:
- 密封不良:包装密封不完整,可能导致食品变质
- 标签错误:标签贴错或信息错误
- 包装破损:包装材料的破损或变形
- 异物污染:包装内的异物或污染物
数据集选择与准备
选择合适的数据集是训练成功的YOLO缺陷检测模型的关键步骤。不同的应用场景需要不同类型的数据集,而数据集的质量直接影响模型的性能。
公开数据集详细介绍
NEU-CLS钢材表面缺陷数据集
这是目前最权威和使用最广泛的钢材表面缺陷检测数据集之一。
数据集详情:
- 来源机构:东北大学(Northeastern University)
- 数据规模:1,800张灰度图像
- 图像尺寸:200×200像素
- 缺陷类别:6种(每类300张图像)
- 标注格式:提供分类和检测两种标注
缺陷类别详解:
- 轧制氧化皮(RS):表面呈现不规则的深色斑块,通常分布不均匀
- 斑块(Pa):表面的浅色或深色斑块状缺陷,边界相对清晰
- 开裂(Cr):线状或网状的裂纹,通常呈现为深色线条
- 点蚀表面(PS):表面的点状凹陷,呈现为密集的小黑点
- 内含物(In):钢材中的杂质在表面的显现,通常为不规则形状
- 划痕(Sc):线状的表面损伤,通常为直线或弧线
使用建议:
- 适合初学者:数据集规模适中,标注质量高,适合初学者练习
- 基准测试:可以作为算法性能的基准测试数据集
- 迁移学习:可以作为预训练数据,用于其他钢材缺陷检测任务
下载方式:
- 官方地址:http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/
- 备用地址:多个学术平台提供镜像下载
PCB缺陷检测数据集
北京大学PCB数据集:
- 数据规模:1,386张图像
- 缺陷类型:6种(缺失孔、鼠咬、开路、短路、杂散、伪铜)
- 图像特点:高分辨率,包含复杂的电路图案
- 标注质量:专业标注,适合学术研究
DeepPCB数据集:
- 数据规模:1,500对图像(模板图像+测试图像)
- 标注方式:像素级标注,支持分割任务
- 应用场景:适合对比检测和异常检测
AITEX纺织品缺陷数据集
数据集特点:
- 材料类型:多种纺织品材料
- 缺陷类型:12种常见纺织品缺陷
- 图像质量:高质量的工业级图像
- 实用性强:来自真实的生产环境
缺陷类型包括:
- 破洞、污渍、色差、纬斜、断经、油污等
MVTec异常检测数据集
这是一个专门用于异常检测的综合性数据集,包含多种工业产品。
数据集特点:
- 产品类型:15种不同的工业产品
- 图像数量:5,000+张高质量图像
- 标注方式:像素级异常标注
- 应用广泛:适合多种异常检测算法
产品类别:
- 纹理类:地毯、格子、皮革、瓷砖、木材等
- 物体类:瓶子、电缆、胶囊、榛子、金属螺母等
数据集质量评估
标注质量检查
高质量的标注是训练成功模型的基础,需要从多个维度评估标注质量:
一致性检查:
- 类别一致性:同一类缺陷在不同图像中的标注是否一致
- 边界一致性:边界框的标注是否准确,是否存在过大或过小的情况
- 标准一致性:不同标注员之间的标注标准是否统一
完整性检查:
- 漏标检查:是否存在明显的缺陷没有被标注
- 重复标注:是否存在同一个缺陷被重复标注的情况
- 边界目标:对于部分在图像边界的目标是否正确处理
准确性检查:
- 类别准确性:标注的类别是否正确
- 位置准确性:边界框的位置是否准确
- 尺寸准确性:边界框的大小是否合适
数据分布分析
类别分布:
- 样本数量分布:各类别的样本数量是否平衡
- 缺陷尺寸分布:不同尺寸缺陷的分布情况
- 缺陷位置分布:缺陷在图像中的位置分布
图像质量分析:
- 分辨率分布:图像分辨率是否一致
- 亮度分布:图像亮度是否均匀
- 对比度分析:图像对比度是否适合检测
数据增强策略
针对缺陷检测的特点,需要设计专门的数据增强策略:
几何变换:
- 旋转:随机旋转0-360度,增加缺陷方向的多样性
- 翻转:水平和垂直翻转,增加数据多样性
- 缩放:0.8-1.2倍的随机缩放,模拟不同的拍摄距离
- 平移:小幅度的随机平移,增加位置多样性
颜色变换:
- 亮度调整:±20%的亮度变化,模拟不同光照条件
- 对比度调整:±15%的对比度变化,增强鲁棒性
- 饱和度调整:对于彩色图像,调整饱和度
- 色调调整:小幅度的色调变化
噪声添加:
- 高斯噪声:添加轻微的高斯噪声,提高抗噪能力
- 椒盐噪声:模拟传感器噪声
- 模糊处理:轻微的模糊处理,模拟运动模糊
高级增强技术:
- Mixup:将两张图像按比例混合
- CutMix:将一张图像的部分区域替换为另一张图像
- Mosaic:将四张图像拼接成一张图像
- Copy-Paste:将缺陷区域复制到其他位置
数据预处理流程
图像预处理
尺寸标准化:
- 目标尺寸选择:根据模型要求选择合适的输入尺寸(如640×640)
- 缩放策略:保持长宽比的缩放,避免图像变形
- 填充策略:对于不符合目标长宽比的图像,使用合适的填充方式
颜色空间转换:
- RGB标准化:将像素值归一化到[0,1]或[-1,1]范围
- 均值减法:减去数据集的均值,提高训练稳定性
- 标准差归一化:除以标准差,进一步标准化数据
质量增强:
- 直方图均衡化:改善图像对比度
- 去噪处理:去除图像噪声
- 锐化处理:增强图像细节
标注格式转换
不同的框架和工具使用不同的标注格式,需要进行格式转换:
YOLO格式:
class_id center_x center_y width height其中所有坐标都是相对于图像尺寸的比例值(0-1之间)。
COCO格式:
{
"id": 1,
"image_id": 1,
"category_id": 1,
"bbox": [x, y, width, height],
"area": area,
"iscrowd": 0
}PASCAL VOC格式:
<annotation>
<object>
<name>defect_type</name>
<bndbox>
<xmin>100</xmin>
<ymin>100</ymin>
<xmax>200</xmax>
<ymax>200</ymax>
</bndbox>
</object>
</annotation>数据集划分策略
划分比例:
- 训练集:70-80%,用于模型训练
- 验证集:10-15%,用于模型选择和超参数调优
- 测试集:10-15%,用于最终性能评估
划分原则:
- 随机划分:确保各个子集的数据分布相似
- 分层划分:保证各类别在各个子集中的比例一致
- 时间划分:对于时序数据,按时间顺序划分
交叉验证:
- K折交叉验证:将数据分为K份,轮流作为验证集
- 留一法:每次留一个样本作为验证集
- 时间序列交叉验证:适用于时序数据的交叉验证方法
环境搭建指南
系统要求与硬件配置
在开始YOLO缺陷检测项目之前,正确配置开发环境是成功的关键。本节将详细介绍硬件要求、软件安装和环境配置的完整流程。
硬件要求分析
GPU配置建议
深度学习训练对GPU的依赖性很强,特别是对于YOLO这样的复杂模型。以下是不同应用场景的GPU配置建议:
入门级配置(学习和小规模实验):
- GPU型号:NVIDIA GTX 1660 Ti / RTX 3060
- 显存要求:6GB以上
- 适用场景:小数据集训练、算法学习、原型验证
- 训练时间:相对较长,但足够完成学习任务
专业级配置(中等规模项目):
- GPU型号:NVIDIA RTX 3070 / RTX 3080 / RTX 4070
- 显存要求:8-12GB
- 适用场景:中等规模数据集、产品开发、性能优化
- 训练时间:较快,能够支持迭代开发
企业级配置(大规模生产项目):
- GPU型号:NVIDIA RTX 3090 / RTX 4090 / A100
- 显存要求:16GB以上
- 适用场景:大规模数据集、多模型训练、生产部署
- 训练时间:最快,支持复杂的实验和优化
CPU和内存配置
虽然GPU是深度学习的主要计算单元,但CPU和内存的配置同样重要:
CPU要求:
- 最低配置:Intel i5-8400 / AMD Ryzen 5 2600
- 推荐配置:Intel i7-10700K / AMD Ryzen 7 3700X
- 高端配置:Intel i9-12900K / AMD Ryzen 9 5900X
内存要求:
- 最低配置:16GB DDR4
- 推荐配置:32GB DDR4
- 高端配置:64GB DDR4或更高
内存的重要性在于数据加载和预处理。大型数据集需要足够的内存来缓存数据,避免频繁的磁盘I/O操作影响训练速度。
存储配置
系统盘:
- 类型:SSD(固态硬盘)
- 容量:至少256GB,推荐512GB以上
- 用途:操作系统、开发环境、常用软件
数据盘:
- 类型:SSD(推荐)或高速HDD
- 容量:根据数据集大小确定,建议1TB以上
- 用途:存储训练数据、模型文件、实验结果
备份存储:
- 类型:网络存储或外部硬盘
- 用途:重要数据备份、模型版本管理
Python环境配置
Python版本选择
选择合适的Python版本对于环境稳定性至关重要:
推荐版本:Python 3.8 - 3.10
- Python 3.8:稳定性最好,兼容性最广
- Python 3.9:性能有所提升,兼容性良好
- Python 3.10:最新特性,但某些库可能存在兼容性问题
避免版本:
- Python 3.7及以下:过于老旧,许多新库不再支持
- Python 3.11及以上:过于新,可能存在兼容性问题
虚拟环境管理
使用虚拟环境可以避免不同项目之间的依赖冲突,强烈推荐使用:
Conda环境管理(推荐):
# 安装Miniconda或Anaconda
# 下载地址:https://docs.conda.io/en/latest/miniconda.html
# 创建新的conda环境
conda create -n yolo_defect python=3.9
# 激活环境
conda activate yolo_defect
# 查看已安装的包
conda list
# 导出环境配置
conda env export > environment.yml
# 从配置文件创建环境
conda env create -f environment.ymlvenv环境管理(Python内置):
# 创建虚拟环境
python -m venv yolo_defect_env
# 激活环境(Windows)
yolo_defect_env\Scripts\activate
# 激活环境(Linux/Mac)
source yolo_defect_env/bin/activate
# 安装包
pip install package_name
# 导出依赖列表
pip freeze > requirements.txt
# 从依赖列表安装
pip install -r requirements.txt深度学习框架安装
PyTorch安装配置
PyTorch是目前最流行的深度学习框架之一,YOLOv5和YOLOv8都基于PyTorch开发:
GPU版本安装:
# 激活虚拟环境
conda activate yolo_defect
# 安装PyTorch(CUDA 11.8版本)
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
# 或使用pip安装
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118CPU版本安装(仅用于测试):
# CPU版本(不推荐用于训练)
conda install pytorch torchvision torchaudio cpuonly -c pytorch安装验证:
import torch
import torchvision
# 检查PyTorch版本
print(f"PyTorch版本: {torch.__version__}")
# 检查CUDA是否可用
print(f"CUDA是否可用: {torch.cuda.is_available()}")
# 检查GPU数量
print(f"GPU数量: {torch.cuda.device_count()}")
# 检查GPU信息
if torch.cuda.is_available():
print(f"GPU名称: {torch.cuda.get_device_name(0)}")
print(f"GPU内存: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.1f} GB")CUDA和cuDNN配置
CUDA是NVIDIA提供的并行计算平台,cuDNN是深度学习加速库:
CUDA安装:
- 访问NVIDIA官网下载CUDA Toolkit
- 选择与PyTorch兼容的CUDA版本
- 按照安装向导完成安装
- 配置环境变量
cuDNN安装:
- 注册NVIDIA开发者账号
- 下载与CUDA版本匹配的cuDNN
- 解压并复制文件到CUDA安装目录
- 配置环境变量
环境变量配置(Windows):
# 添加到系统PATH
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp
# 添加CUDA_PATH
CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8YOLO框架安装
YOLOv8 (Ultralytics)安装
YOLOv8是目前最新且最易用的YOLO版本,推荐初学者使用:
# 激活虚拟环境
conda activate yolo_defect
# 安装ultralytics包
pip install ultralytics
# 验证安装
yolo version
# 或在Python中验证
python -c "from ultralytics import YOLO; print('YOLOv8安装成功')"YOLOv5安装
YOLOv5也是一个优秀的选择,特别适合需要自定义修改的场景:
# 克隆YOLOv5仓库
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
# 安装依赖
pip install -r requirements.txt
# 验证安装
python detect.py --source data/images --weights yolov5s.pt依赖包安装
除了主要框架外,还需要安装一些辅助包:
# 图像处理
pip install opencv-python pillow
# 数据处理
pip install numpy pandas matplotlib seaborn
# 科学计算
pip install scipy scikit-learn
# 可视化
pip install tensorboard wandb
# 数据标注工具
pip install labelimg roboflow
# Jupyter notebook
pip install jupyter notebook ipywidgets
# 其他实用工具
pip install tqdm pyyaml开发工具配置
IDE选择与配置
Visual Studio Code(推荐):
VS Code是目前最受欢迎的代码编辑器,具有丰富的插件生态:
必装插件:
- Python:Python语言支持
- Pylance:Python智能提示
- Jupyter:Jupyter notebook支持
- GitLens:Git版本控制增强
- Remote-SSH:远程开发支持
配置文件示例(.vscode/settings.json):
{
"python.defaultInterpreterPath": "./yolo_defect_env/bin/python",
"python.linting.enabled": true,
"python.linting.pylintEnabled": true,
"python.formatting.provider": "black",
"editor.formatOnSave": true,
"files.autoSave": "afterDelay",
"files.autoSaveDelay": 1000
}PyCharm Professional:
PyCharm是专业的Python IDE,特别适合大型项目开发:
优势:
- 强大的调试功能
- 优秀的代码重构支持
- 内置数据库工具
- 专业的版本控制集成
配置要点:
- 配置Python解释器指向虚拟环境
- 设置代码风格和格式化规则
- 配置远程开发环境
- 安装深度学习相关插件
Jupyter Lab/Notebook:
Jupyter是数据科学和机器学习的标准工具:
# 安装Jupyter Lab
pip install jupyterlab
# 启动Jupyter Lab
jupyter lab
# 安装有用的扩展
pip install jupyterlab-git
pip install jupyterlab-lsp版本控制配置
Git配置:
# 全局配置
git config --global user.name "Your Name"
git config --global user.email "your.email@example.com"
# 配置默认编辑器
git config --global core.editor "code --wait"
# 配置换行符处理
git config --global core.autocrlf input # Linux/Mac
git config --global core.autocrlf true # Windows项目结构建议:
yolo_defect_project/
├── data/
│ ├── raw/ # 原始数据
│ ├── processed/ # 预处理后的数据
│ ├── train/ # 训练数据
│ ├── val/ # 验证数据
│ └── test/ # 测试数据
├── models/
│ ├── pretrained/ # 预训练模型
│ ├── trained/ # 训练好的模型
│ └── configs/ # 模型配置文件
├── src/
│ ├── data/ # 数据处理脚本
│ ├── models/ # 模型定义
│ ├── training/ # 训练脚本
│ ├── evaluation/ # 评估脚本
│ └── utils/ # 工具函数
├── notebooks/ # Jupyter notebooks
├── experiments/ # 实验记录
├── docs/ # 文档
├── requirements.txt # 依赖列表
├── README.md # 项目说明
└── .gitignore # Git忽略文件数据准备实战
数据下载与组织
NEU-CLS数据集下载:
import os
import urllib.request
import zipfile
from pathlib import Path
def download_neu_cls_dataset(data_dir="./data/raw"):
"""下载NEU-CLS数据集"""
# 创建数据目录
Path(data_dir).mkdir(parents=True, exist_ok=True)
# 数据集URL(示例,实际需要从官方网站获取)
dataset_url = "http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/"
print("请手动从以下网址下载NEU-CLS数据集:")
print(dataset_url)
print(f"下载后请解压到:{data_dir}")
# 检查数据集是否存在
neu_cls_path = Path(data_dir) / "NEU-CLS"
if neu_cls_path.exists():
print("数据集已存在")
return str(neu_cls_path)
else:
print("请下载并解压数据集到指定目录")
return None
# 下载数据集
dataset_path = download_neu_cls_dataset()数据集结构分析:
import os
from collections import defaultdict
from pathlib import Path
def analyze_dataset_structure(dataset_path):
"""分析数据集结构"""
dataset_path = Path(dataset_path)
# 统计各类别的图像数量
class_counts = defaultdict(int)
total_images = 0
for class_dir in dataset_path.iterdir():
if class_dir.is_dir():
image_count = len(list(class_dir.glob("*.jpg"))) + len(list(class_dir.glob("*.png")))
class_counts[class_dir.name] = image_count
total_images += image_count
# 打印统计信息
print("数据集结构分析:")
print(f"总图像数量: {total_images}")
print(f"类别数量: {len(class_counts)}")
print("\n各类别图像数量:")
for class_name, count in sorted(class_counts.items()):
percentage = (count / total_images) * 100
print(f"{class_name}: {count} 张 ({percentage:.1f}%)")
return class_counts
# 分析数据集
if dataset_path:
class_counts = analyze_dataset_structure(dataset_path)数据格式转换
YOLO格式转换脚本:
import json
import xml.etree.ElementTree as ET
from pathlib import Path
import cv2
class DatasetConverter:
"""数据集格式转换器"""
def __init__(self, class_names):
self.class_names = class_names
self.class_to_id = {name: idx for idx, name in enumerate(class_names)}
def pascal_voc_to_yolo(self, xml_path, img_path):
"""将PASCAL VOC格式转换为YOLO格式"""
# 读取XML文件
tree = ET.parse(xml_path)
root = tree.getroot()
# 获取图像尺寸
img = cv2.imread(str(img_path))
img_height, img_width = img.shape[:2]
# 解析标注信息
annotations = []
for obj in root.findall('object'):
class_name = obj.find('name').text
if class_name not in self.class_to_id:
continue
class_id = self.class_to_id[class_name]
# 获取边界框坐标
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
# 转换为YOLO格式(相对坐标)
center_x = (xmin + xmax) / 2.0 / img_width
center_y = (ymin + ymax) / 2.0 / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
annotations.append(f"{class_id} {center_x:.6f} {center_y:.6f} {width:.6f} {height:.6f}")
return annotations
def coco_to_yolo(self, coco_json_path, output_dir):
"""将COCO格式转换为YOLO格式"""
with open(coco_json_path, 'r') as f:
coco_data = json.load(f)
# 创建输出目录
output_dir = Path(output_dir)
output_dir.mkdir(parents=True, exist_ok=True)
# 创建图像ID到文件名的映射
img_id_to_filename = {img['id']: img['file_name'] for img in coco_data['images']}
img_id_to_size = {img['id']: (img['width'], img['height']) for img in coco_data['images']}
# 按图像分组标注
annotations_by_img = defaultdict(list)
for ann in coco_data['annotations']:
annotations_by_img[ann['image_id']].append(ann)
# 转换每个图像的标注
for img_id, annotations in annotations_by_img.items():
filename = img_id_to_filename[img_id]
img_width, img_height = img_id_to_size[img_id]
# 生成YOLO格式标注
yolo_annotations = []
for ann in annotations:
class_id = ann['category_id'] - 1 # COCO类别ID从1开始
# COCO格式:[x, y, width, height](左上角坐标)
x, y, w, h = ann['bbox']
# 转换为YOLO格式(中心点坐标,相对尺寸)
center_x = (x + w / 2) / img_width
center_y = (y + h / 2) / img_height
rel_width = w / img_width
rel_height = h / img_height
yolo_annotations.append(f"{class_id} {center_x:.6f} {center_y:.6f} {rel_width:.6f} {rel_height:.6f}")
# 保存YOLO格式标注文件
txt_filename = Path(filename).stem + '.txt'
txt_path = output_dir / txt_filename
with open(txt_path, 'w') as f:
f.write('\n'.join(yolo_annotations))
# 使用示例
class_names = ['rolled-in_scale', 'patches', 'crazing', 'pitted_surface', 'inclusion', 'scratches']
converter = DatasetConverter(class_names)数据增强实现:
import albumentations as A
import cv2
import numpy as np
from pathlib import Path
import random
class DefectDataAugmentation:
"""缺陷检测专用数据增强"""
def __init__(self, img_size=640):
self.img_size = img_size
# 定义增强管道
self.train_transform = A.Compose([
# 几何变换
A.Rotate(limit=30, p=0.5),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.3),
A.RandomScale(scale_limit=0.2, p=0.5),
A.ShiftScaleRotate(
shift_limit=0.1,
scale_limit=0.1,
rotate_limit=15,
p=0.5
),
# 颜色变换
A.RandomBrightnessContrast(
brightness_limit=0.2,
contrast_limit=0.2,
p=0.5
),
A.HueSaturationValue(
hue_shift_limit=10,
sat_shift_limit=20,
val_shift_limit=20,
p=0.3
),
# 噪声和模糊
A.GaussNoise(var_limit=(10, 50), p=0.3),
A.GaussianBlur(blur_limit=3, p=0.2),
A.MotionBlur(blur_limit=3, p=0.2),
# 尺寸调整
A.Resize(self.img_size, self.img_size),
# 归一化
A.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
], bbox_params=A.BboxParams(
format='yolo',
label_fields=['class_labels']
))
self.val_transform = A.Compose([
A.Resize(self.img_size, self.img_size),
A.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
], bbox_params=A.BboxParams(
format='yolo',
label_fields=['class_labels']
))
def augment_image(self, image, bboxes, class_labels, is_training=True):
"""对图像和标注进行增强"""
transform = self.train_transform if is_training else self.val_transform
# 应用变换
transformed = transform(
image=image,
bboxes=bboxes,
class_labels=class_labels
)
return transformed['image'], transformed['bboxes'], transformed['class_labels']
def create_mosaic(self, images, bboxes_list, class_labels_list):
"""创建Mosaic增强(4张图像拼接)"""
# 创建输出图像
mosaic_img = np.zeros((self.img_size, self.img_size, 3), dtype=np.uint8)
mosaic_bboxes = []
mosaic_labels = []
# 随机选择拼接点
cut_x = random.randint(self.img_size // 4, 3 * self.img_size // 4)
cut_y = random.randint(self.img_size // 4, 3 * self.img_size // 4)
# 定义四个区域
regions = [
(0, 0, cut_x, cut_y), # 左上
(cut_x, 0, self.img_size, cut_y), # 右上
(0, cut_y, cut_x, self.img_size), # 左下
(cut_x, cut_y, self.img_size, self.img_size) # 右下
]
for i, (img, bboxes, labels) in enumerate(zip(images, bboxes_list, class_labels_list)):
if i >= 4:
break
x1, y1, x2, y2 = regions[i]
region_w, region_h = x2 - x1, y2 - y1
# 调整图像大小以适应区域
img_resized = cv2.resize(img, (region_w, region_h))
# 放置图像
mosaic_img[y1:y2, x1:x2] = img_resized
# 调整边界框坐标
for bbox, label in zip(bboxes, labels):
# YOLO格式:center_x, center_y, width, height(相对坐标)
center_x, center_y, width, height = bbox
# 转换为绝对坐标
abs_center_x = center_x * region_w + x1
abs_center_y = center_y * region_h + y1
abs_width = width * region_w
abs_height = height * region_h
# 检查边界框是否在图像范围内
if (abs_center_x > 0 and abs_center_x < self.img_size and
abs_center_y > 0 and abs_center_y < self.img_size):
# 转换回相对坐标
rel_center_x = abs_center_x / self.img_size
rel_center_y = abs_center_y / self.img_size
rel_width = abs_width / self.img_size
rel_height = abs_height / self.img_size
mosaic_bboxes.append([rel_center_x, rel_center_y, rel_width, rel_height])
mosaic_labels.append(label)
return mosaic_img, mosaic_bboxes, mosaic_labels
# 使用示例
augmentation = DefectDataAugmentation(img_size=640)
# 加载图像和标注
image = cv2.imread("sample_image.jpg")
bboxes = [[0.5, 0.5, 0.2, 0.3]] # YOLO格式
class_labels = [0]
# 应用增强
aug_image, aug_bboxes, aug_labels = augmentation.augment_image(
image, bboxes, class_labels, is_training=True
)数据集划分脚本:
import random
import shutil
from pathlib import Path
from sklearn.model_selection import train_test_split
def split_dataset(dataset_path, output_path, train_ratio=0.7, val_ratio=0.15, test_ratio=0.15):
"""划分数据集为训练、验证和测试集"""
dataset_path = Path(dataset_path)
output_path = Path(output_path)
# 创建输出目录
for split in ['train', 'val', 'test']:
(output_path / split / 'images').mkdir(parents=True, exist_ok=True)
(output_path / split / 'labels').mkdir(parents=True, exist_ok=True)
# 收集所有图像文件
image_files = []
for ext in ['*.jpg', '*.jpeg', '*.png', '*.bmp']:
image_files.extend(dataset_path.glob(f"**/{ext}"))
# 随机打乱
random.shuffle(image_files)
# 计算划分点
total_count = len(image_files)
train_count = int(total_count * train_ratio)
val_count = int(total_count * val_ratio)
# 划分数据
train_files = image_files[:train_count]
val_files = image_files[train_count:train_count + val_count]
test_files = image_files[train_count + val_count:]
# 复制文件
for split_name, files in [('train', train_files), ('val', val_files), ('test', test_files)]:
for img_file in files:
# 复制图像文件
dst_img = output_path / split_name / 'images' / img_file.name
shutil.copy2(img_file, dst_img)
# 复制对应的标注文件
label_file = img_file.with_suffix('.txt')
if label_file.exists():
dst_label = output_path / split_name / 'labels' / label_file.name
shutil.copy2(label_file, dst_label)
print(f"数据集划分完成:")
print(f"训练集: {len(train_files)} 张")
print(f"验证集: {len(val_files)} 张")
print(f"测试集: {len(test_files)} 张")
# 使用示例
split_dataset(
dataset_path="./data/processed/neu_cls_yolo",
output_path="./data/splits",
train_ratio=0.7,
val_ratio=0.15,
test_ratio=0.15
)这样,我们就完成了完整的环境搭建和数据准备流程。接下来的章节将介绍如何使用准备好的环境和数据来训练YOLO模型。
模型训练实战
训练前的准备工作
在开始训练YOLO模型之前,需要完成一系列准备工作,确保训练过程顺利进行并获得最佳效果。
配置文件准备
YOLO训练需要一个配置文件来定义数据集路径、类别信息和训练参数。以下是一个完整的配置文件示例:
# dataset.yaml - 数据集配置文件
# 数据集路径
path: ./data/splits # 数据集根目录
train: train/images # 训练集图像路径(相对于path)
val: val/images # 验证集图像路径(相对于path)
test: test/images # 测试集图像路径(相对于path)
# 类别数量
nc: 6 # 类别数量
# 类别名称
names:
0: rolled-in_scale # 轧制氧化皮
1: patches # 斑块
2: crazing # 开裂
3: pitted_surface # 点蚀表面
4: inclusion # 内含物
5: scratches # 划痕
# 数据集信息
download: false # 是否需要下载数据集
description: "NEU-CLS钢材表面缺陷检测数据集"预训练模型选择
选择合适的预训练模型是成功训练的关键。不同的模型在精度和速度之间有不同的权衡:
YOLOv8模型系列对比:
| 模型 | 参数量 | 模型大小 | mAP@0.5 | 推理速度(ms) | 适用场景 |
|---|---|---|---|---|---|
| YOLOv8n | 3.2M | 6.2MB | 37.3% | 0.99 | 边缘设备、实时应用 |
| YOLOv8s | 11.2M | 21.5MB | 44.9% | 1.20 | 平衡精度和速度 |
| YOLOv8m | 25.9M | 49.7MB | 50.2% | 1.83 | 高精度要求 |
| YOLOv8l | 43.7M | 83.7MB | 52.9% | 2.39 | 离线处理、高精度 |
| YOLOv8x | 68.2M | 130.5MB | 53.9% | 3.53 | 最高精度要求 |
模型选择建议:
初学者推荐:YOLOv8s - 在精度和训练时间之间取得良好平衡,适合学习和实验。
生产环境:根据具体需求选择:
- 实时检测:YOLOv8n或YOLOv8s
- 高精度要求:YOLOv8m或YOLOv8l
- 离线批处理:YOLOv8x
硬件资源评估
训练前需要评估硬件资源是否满足要求:
import torch
import psutil
import GPUtil
def check_system_resources():
"""检查系统资源"""
print("=== 系统资源检查 ===")
# CPU信息
cpu_count = psutil.cpu_count()
cpu_percent = psutil.cpu_percent(interval=1)
print(f"CPU核心数: {cpu_count}")
print(f"CPU使用率: {cpu_percent}%")
# 内存信息
memory = psutil.virtual_memory()
print(f"总内存: {memory.total / (1024**3):.1f} GB")
print(f"可用内存: {memory.available / (1024**3):.1f} GB")
print(f"内存使用率: {memory.percent}%")
# GPU信息
if torch.cuda.is_available():
gpu_count = torch.cuda.device_count()
print(f"\nGPU数量: {gpu_count}")
for i in range(gpu_count):
gpu_name = torch.cuda.get_device_name(i)
gpu_memory = torch.cuda.get_device_properties(i).total_memory / (1024**3)
print(f"GPU {i}: {gpu_name}")
print(f"GPU {i} 显存: {gpu_memory:.1f} GB")
# 检查GPU使用情况
torch.cuda.set_device(i)
allocated = torch.cuda.memory_allocated() / (1024**3)
cached = torch.cuda.memory_reserved() / (1024**3)
print(f"GPU {i} 已分配显存: {allocated:.1f} GB")
print(f"GPU {i} 缓存显存: {cached:.1f} GB")
else:
print("\n未检测到CUDA GPU")
# 磁盘空间
disk = psutil.disk_usage('.')
print(f"\n磁盘总空间: {disk.total / (1024**3):.1f} GB")
print(f"磁盘可用空间: {disk.free / (1024**3):.1f} GB")
print(f"磁盘使用率: {(disk.used / disk.total) * 100:.1f}%")
# 检查系统资源
check_system_resources()YOLOv8训练详解
基础训练脚本
以下是一个完整的YOLOv8训练脚本:
from ultralytics import YOLO
import torch
import yaml
from pathlib import Path
import wandb
import os
class YOLOTrainer:
"""YOLO训练器"""
def __init__(self, model_name='yolov8s.pt', data_config='dataset.yaml'):
"""
初始化训练器
Args:
model_name: 预训练模型名称
data_config: 数据集配置文件路径
"""
self.model_name = model_name
self.data_config = data_config
self.model = None
def setup_model(self):
"""设置模型"""
print(f"加载模型: {self.model_name}")
self.model = YOLO(self.model_name)
# 打印模型信息
print(f"模型参数量: {sum(p.numel() for p in self.model.model.parameters()):,}")
print(f"可训练参数: {sum(p.numel() for p in self.model.model.parameters() if p.requires_grad):,}")
def setup_wandb(self, project_name="yolo-defect-detection", run_name=None):
"""设置Weights & Biases监控"""
try:
wandb.init(
project=project_name,
name=run_name,
config={
"model": self.model_name,
"dataset": self.data_config,
"framework": "YOLOv8"
}
)
print("Wandb初始化成功")
return True
except Exception as e:
print(f"Wandb初始化失败: {e}")
return False
def train(self,
epochs=100,
imgsz=640,
batch_size=16,
lr0=0.01,
weight_decay=0.0005,
warmup_epochs=3,
patience=50,
save_period=10,
device='auto',
workers=8,
project='runs/train',
name='exp',
resume=False,
**kwargs):
"""
训练模型
Args:
epochs: 训练轮数
imgsz: 输入图像尺寸
batch_size: 批次大小
lr0: 初始学习率
weight_decay: 权重衰减
warmup_epochs: 预热轮数
patience: 早停耐心值
save_period: 保存周期
device: 设备选择
workers: 数据加载进程数
project: 项目目录
name: 实验名称
resume: 是否恢复训练
"""
if self.model is None:
self.setup_model()
print("开始训练...")
print(f"训练参数:")
print(f" - 轮数: {epochs}")
print(f" - 图像尺寸: {imgsz}")
print(f" - 批次大小: {batch_size}")
print(f" - 学习率: {lr0}")
print(f" - 设备: {device}")
# 训练参数
train_args = {
'data': self.data_config,
'epochs': epochs,
'imgsz': imgsz,
'batch': batch_size,
'lr0': lr0,
'weight_decay': weight_decay,
'warmup_epochs': warmup_epochs,
'patience': patience,
'save_period': save_period,
'device': device,
'workers': workers,
'project': project,
'name': name,
'resume': resume,
'verbose': True,
'seed': 42, # 设置随机种子确保可重复性
**kwargs
}
# 开始训练
try:
results = self.model.train(**train_args)
print("训练完成!")
return results
except Exception as e:
print(f"训练过程中出现错误: {e}")
raise
def validate(self, data=None, imgsz=640, batch=16, device='auto'):
"""验证模型"""
if self.model is None:
raise ValueError("模型未初始化,请先调用setup_model()")
data = data or self.data_config
print(f"开始验证,数据集: {data}")
results = self.model.val(
data=data,
imgsz=imgsz,
batch=batch,
device=device,
verbose=True
)
return results
def export_model(self, format='onnx', imgsz=640, **kwargs):
"""导出模型"""
if self.model is None:
raise ValueError("模型未初始化")
print(f"导出模型格式: {format}")
export_args = {
'format': format,
'imgsz': imgsz,
**kwargs
}
try:
path = self.model.export(**export_args)
print(f"模型导出成功: {path}")
return path
except Exception as e:
print(f"模型导出失败: {e}")
raise
# 使用示例
def main():
"""主训练函数"""
# 创建训练器
trainer = YOLOTrainer(
model_name='yolov8s.pt',
data_config='dataset.yaml'
)
# 设置模型
trainer.setup_model()
# 设置监控(可选)
trainer.setup_wandb(
project_name="steel-defect-detection",
run_name="yolov8s-baseline"
)
# 开始训练
results = trainer.train(
epochs=100,
imgsz=640,
batch_size=16,
lr0=0.01,
patience=20,
save_period=10,
device='auto',
workers=8,
project='runs/train',
name='steel_defect_v1'
)
# 验证模型
val_results = trainer.validate()
# 导出模型
trainer.export_model(format='onnx')
print("训练流程完成!")
if __name__ == "__main__":
main()超参数调优策略
超参数调优是提高模型性能的关键步骤。以下是系统性的调优方法:
学习率调优:
import optuna
from ultralytics import YOLO
def objective(trial):
"""Optuna优化目标函数"""
# 建议的超参数范围
lr0 = trial.suggest_float('lr0', 1e-5, 1e-1, log=True)
weight_decay = trial.suggest_float('weight_decay', 1e-6, 1e-2, log=True)
warmup_epochs = trial.suggest_int('warmup_epochs', 1, 5)
batch_size = trial.suggest_categorical('batch_size', [8, 16, 32])
# 创建模型
model = YOLO('yolov8s.pt')
# 训练模型
results = model.train(
data='dataset.yaml',
epochs=50, # 较少的轮数用于快速评估
imgsz=640,
batch=batch_size,
lr0=lr0,
weight_decay=weight_decay,
warmup_epochs=warmup_epochs,
patience=10,
verbose=False,
project='runs/optuna',
name=f'trial_{trial.number}'
)
# 返回验证集mAP作为优化目标
return results.results_dict['metrics/mAP50(B)']
def hyperparameter_optimization(n_trials=50):
"""超参数优化"""
# 创建Optuna研究
study = optuna.create_study(direction='maximize')
# 开始优化
study.optimize(objective, n_trials=n_trials)
# 打印最佳参数
print("最佳参数:")
for key, value in study.best_params.items():
print(f" {key}: {value}")
print(f"最佳mAP: {study.best_value:.4f}")
return study.best_params
# 运行超参数优化
# best_params = hyperparameter_optimization(n_trials=20)数据增强参数调优:
def optimize_augmentation():
"""优化数据增强参数"""
augmentation_configs = [
# 基础配置
{
'hsv_h': 0.015,
'hsv_s': 0.7,
'hsv_v': 0.4,
'degrees': 0.0,
'translate': 0.1,
'scale': 0.5,
'shear': 0.0,
'perspective': 0.0,
'flipud': 0.0,
'fliplr': 0.5,
'mosaic': 1.0,
'mixup': 0.0
},
# 强增强配置
{
'hsv_h': 0.02,
'hsv_s': 0.8,
'hsv_v': 0.5,
'degrees': 10.0,
'translate': 0.2,
'scale': 0.8,
'shear': 2.0,
'perspective': 0.001,
'flipud': 0.5,
'fliplr': 0.5,
'mosaic': 1.0,
'mixup': 0.1
},
# 轻增强配置
{
'hsv_h': 0.01,
'hsv_s': 0.5,
'hsv_v': 0.3,
'degrees': 5.0,
'translate': 0.05,
'scale': 0.3,
'shear': 0.0,
'perspective': 0.0,
'flipud': 0.0,
'fliplr': 0.5,
'mosaic': 0.5,
'mixup': 0.0
}
]
best_map = 0
best_config = None
for i, config in enumerate(augmentation_configs):
print(f"测试增强配置 {i+1}/3")
model = YOLO('yolov8s.pt')
results = model.train(
data='dataset.yaml',
epochs=30,
imgsz=640,
batch=16,
verbose=False,
project='runs/augmentation',
name=f'aug_config_{i}',
**config
)
current_map = results.results_dict['metrics/mAP50(B)']
print(f"配置 {i+1} mAP: {current_map:.4f}")
if current_map > best_map:
best_map = current_map
best_config = config
print(f"最佳增强配置 mAP: {best_map:.4f}")
print("最佳配置参数:")
for key, value in best_config.items():
print(f" {key}: {value}")
return best_config
# 运行增强参数优化
# best_aug_config = optimize_augmentation()训练监控与调试
实时监控设置
训练过程的监控对于及时发现问题和调整策略至关重要:
import matplotlib.pyplot as plt
import pandas as pd
from pathlib import Path
import json
class TrainingMonitor:
"""训练监控器"""
def __init__(self, log_dir):
self.log_dir = Path(log_dir)
self.metrics_history = []
def parse_results(self, results_file):
"""解析训练结果"""
results_path = Path(results_file)
if not results_path.exists():
print(f"结果文件不存在: {results_file}")
return None
# 读取CSV结果文件
df = pd.read_csv(results_file)
return df
def plot_training_curves(self, results_df, save_path=None):
"""绘制训练曲线"""
fig, axes = plt.subplots(2, 3, figsize=(18, 12))
fig.suptitle('Training Metrics', fontsize=16)
# 损失曲线
axes[0, 0].plot(results_df['epoch'], results_df['train/box_loss'], label='Train Box Loss')
axes[0, 0].plot(results_df['epoch'], results_df['val/box_loss'], label='Val Box Loss')
axes[0, 0].set_title('Box Loss')
axes[0, 0].set_xlabel('Epoch')
axes[0, 0].set_ylabel('Loss')
axes[0, 0].legend()
axes[0, 0].grid(True)
axes[0, 1].plot(results_df['epoch'], results_df['train/cls_loss'], label='Train Cls Loss')
axes[0, 1].plot(results_df['epoch'], results_df['val/cls_loss'], label='Val Cls Loss')
axes[0, 1].set_title('Classification Loss')
axes[0, 1].set_xlabel('Epoch')
axes[0, 1].set_ylabel('Loss')
axes[0, 1].legend()
axes[0, 1].grid(True)
axes[0, 2].plot(results_df['epoch'], results_df['train/dfl_loss'], label='Train DFL Loss')
axes[0, 2].plot(results_df['epoch'], results_df['val/dfl_loss'], label='Val DFL Loss')
axes[0, 2].set_title('DFL Loss')
axes[0, 2].set_xlabel('Epoch')
axes[0, 2].set_ylabel('Loss')
axes[0, 2].legend()
axes[0, 2].grid(True)
# 精度曲线
axes[1, 0].plot(results_df['epoch'], results_df['metrics/precision(B)'], label='Precision')
axes[1, 0].plot(results_df['epoch'], results_df['metrics/recall(B)'], label='Recall')
axes[1, 0].set_title('Precision & Recall')
axes[1, 0].set_xlabel('Epoch')
axes[1, 0].set_ylabel('Score')
axes[1, 0].legend()
axes[1, 0].grid(True)
axes[1, 1].plot(results_df['epoch'], results_df['metrics/mAP50(B)'], label='mAP@0.5')
axes[1, 1].plot(results_df['epoch'], results_df['metrics/mAP50-95(B)'], label='mAP@0.5:0.95')
axes[1, 1].set_title('mAP Metrics')
axes[1, 1].set_xlabel('Epoch')
axes[1, 1].set_ylabel('mAP')
axes[1, 1].legend()
axes[1, 1].grid(True)
# 学习率曲线
if 'lr/pg0' in results_df.columns:
axes[1, 2].plot(results_df['epoch'], results_df['lr/pg0'], label='Learning Rate')
axes[1, 2].set_title('Learning Rate')
axes[1, 2].set_xlabel('Epoch')
axes[1, 2].set_ylabel('LR')
axes[1, 2].legend()
axes[1, 2].grid(True)
plt.tight_layout()
if save_path:
plt.savefig(save_path, dpi=300, bbox_inches='tight')
print(f"训练曲线已保存到: {save_path}")
plt.show()
def analyze_training_stability(self, results_df):
"""分析训练稳定性"""
print("=== 训练稳定性分析 ===")
# 检查损失是否收敛
final_epochs = results_df.tail(10)
box_loss_std = final_epochs['val/box_loss'].std()
cls_loss_std = final_epochs['val/cls_loss'].std()
print(f"最后10轮验证损失标准差:")
print(f" Box Loss: {box_loss_std:.6f}")
print(f" Cls Loss: {cls_loss_std:.6f}")
# 检查是否过拟合
train_loss = results_df['train/box_loss'].iloc[-1]
val_loss = results_df['val/box_loss'].iloc[-1]
overfitting_ratio = val_loss / train_loss
print(f"\n过拟合检查:")
print(f" 训练损失: {train_loss:.4f}")
print(f" 验证损失: {val_loss:.4f}")
print(f" 比值: {overfitting_ratio:.2f}")
if overfitting_ratio > 1.5:
print(" ⚠️ 可能存在过拟合")
elif overfitting_ratio < 1.1:
print(" ✅ 训练良好")
else:
print(" ℹ️ 轻微过拟合,可接受")
# 检查最佳性能
best_map = results_df['metrics/mAP50(B)'].max()
best_epoch = results_df.loc[results_df['metrics/mAP50(B)'].idxmax(), 'epoch']
print(f"\n最佳性能:")
print(f" 最佳mAP@0.5: {best_map:.4f}")
print(f" 最佳轮次: {best_epoch}")
return {
'box_loss_std': box_loss_std,
'cls_loss_std': cls_loss_std,
'overfitting_ratio': overfitting_ratio,
'best_map': best_map,
'best_epoch': best_epoch
}
# 使用示例
monitor = TrainingMonitor('runs/train/steel_defect_v1')
results_df = monitor.parse_results('runs/train/steel_defect_v1/results.csv')
if results_df is not None:
monitor.plot_training_curves(results_df, 'training_curves.png')
stability_analysis = monitor.analyze_training_stability(results_df)常见训练问题诊断
def diagnose_training_issues(results_df):
"""诊断训练问题"""
print("=== 训练问题诊断 ===")
issues = []
# 1. 检查损失是否下降
initial_loss = results_df['val/box_loss'].head(5).mean()
final_loss = results_df['val/box_loss'].tail(5).mean()
loss_reduction = (initial_loss - final_loss) / initial_loss
if loss_reduction < 0.1:
issues.append("损失下降不明显,可能学习率过小或数据质量问题")
# 2. 检查损失震荡
loss_diff = results_df['val/box_loss'].diff().abs()
avg_oscillation = loss_diff.mean()
if avg_oscillation > 0.1:
issues.append("损失震荡较大,可能学习率过大")
# 3. 检查mAP提升
initial_map = results_df['metrics/mAP50(B)'].head(10).mean()
final_map = results_df['metrics/mAP50(B)'].tail(10).mean()
map_improvement = (final_map - initial_map) / initial_map
if map_improvement < 0.2:
issues.append("mAP提升有限,可能需要调整模型或数据")
# 4. 检查早停
best_epoch = results_df.loc[results_df['metrics/mAP50(B)'].idxmax(), 'epoch']
total_epochs = len(results_df)
if best_epoch < total_epochs * 0.7:
issues.append("最佳性能出现较早,可能需要早停或调整学习率衰减")
# 5. 检查类别不平衡影响
if 'metrics/precision(B)' in results_df.columns and 'metrics/recall(B)' in results_df.columns:
final_precision = results_df['metrics/precision(B)'].iloc[-1]
final_recall = results_df['metrics/recall(B)'].iloc[-1]
if abs(final_precision - final_recall) > 0.2:
issues.append("精确率和召回率差异较大,可能存在类别不平衡")
# 输出诊断结果
if issues:
print("发现以下问题:")
for i, issue in enumerate(issues, 1):
print(f" {i}. {issue}")
else:
print("✅ 未发现明显问题,训练状态良好")
# 提供改进建议
print("\n改进建议:")
if loss_reduction < 0.1:
print(" - 尝试增加学习率")
print(" - 检查数据质量和标注准确性")
print(" - 考虑使用更强的数据增强")
if avg_oscillation > 0.1:
print(" - 减小学习率")
print(" - 使用学习率调度器")
print(" - 增加批次大小")
if map_improvement < 0.2:
print(" - 尝试更大的模型")
print(" - 增加训练数据")
print(" - 调整损失函数权重")
return issues
# 使用诊断功能
if results_df is not None:
issues = diagnose_training_issues(results_df)模型评估与验证
全面的模型评估
训练完成后,需要对模型进行全面的评估,以确保其在实际应用中的可靠性:
import numpy as np
from sklearn.metrics import confusion_matrix, classification_report
import seaborn as sns
from ultralytics import YOLO
class ModelEvaluator:
"""模型评估器"""
def __init__(self, model_path, data_config):
self.model = YOLO(model_path)
self.data_config = data_config
def comprehensive_evaluation(self, test_data_path=None):
"""全面评估模型"""
print("=== 开始全面模型评估 ===")
# 1. 基础验证指标
print("1. 计算基础验证指标...")
val_results = self.model.val(
data=self.data_config,
split='test' if test_data_path else 'val',
imgsz=640,
batch=16,
verbose=True
)
# 2. 详细的类别性能分析
print("2. 分析各类别性能...")
self.analyze_class_performance(val_results)
# 3. 置信度阈值分析
print("3. 分析置信度阈值...")
self.analyze_confidence_threshold()
# 4. 错误案例分析
print("4. 分析错误案例...")
self.analyze_failure_cases()
return val_results
def analyze_class_performance(self, val_results):
"""分析各类别性能"""
# 获取类别名称
class_names = self.model.names
# 打印各类别的详细指标
print("\n各类别性能详情:")
print("-" * 80)
print(f"{'类别':<15} {'精确率':<10} {'召回率':<10} {'mAP@0.5':<10} {'样本数':<10}")
print("-" * 80)
# 这里需要根据实际的val_results结构来获取各类别指标
# 以下是示例代码,实际使用时需要根据YOLOv8的输出格式调整
for i, class_name in class_names.items():
# 获取该类别的指标(需要根据实际输出调整)
precision = val_results.results_dict.get(f'metrics/precision({i})', 0)
recall = val_results.results_dict.get(f'metrics/recall({i})', 0)
map50 = val_results.results_dict.get(f'metrics/mAP50({i})', 0)
print(f"{class_name:<15} {precision:<10.3f} {recall:<10.3f} {map50:<10.3f}")
print("-" * 80)
def analyze_confidence_threshold(self, conf_range=(0.1, 0.9), step=0.1):
"""分析不同置信度阈值下的性能"""
print(f"\n置信度阈值分析 (范围: {conf_range[0]}-{conf_range[1]}):")
print("-" * 60)
print(f"{'阈值':<8} {'精确率':<10} {'召回率':<10} {'F1分数':<10}")
print("-" * 60)
best_f1 = 0
best_conf = 0
for conf in np.arange(conf_range[0], conf_range[1] + step, step):
# 使用不同置信度阈值进行验证
results = self.model.val(
data=self.data_config,
conf=conf,
verbose=False
)
precision = results.results_dict.get('metrics/precision(B)', 0)
recall = results.results_dict.get('metrics/recall(B)', 0)
f1 = 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
print(f"{conf:<8.1f} {precision:<10.3f} {recall:<10.3f} {f1:<10.3f}")
if f1 > best_f1:
best_f1 = f1
best_conf = conf
print("-" * 60)
print(f"最佳置信度阈值: {best_conf:.1f} (F1: {best_f1:.3f})")
return best_conf, best_f1
def analyze_failure_cases(self, num_samples=20):
"""分析失败案例"""
print(f"\n分析失败案例 (样本数: {num_samples}):")
# 在验证集上进行预测
results = self.model.predict(
source='data/splits/val/images',
conf=0.25,
save=False,
verbose=False
)
failure_types = {
'false_positive': 0, # 误检
'false_negative': 0, # 漏检
'wrong_class': 0, # 类别错误
'poor_localization': 0 # 定位不准
}
# 这里需要实现具体的失败案例分析逻辑
# 比较预测结果与真实标注,统计不同类型的错误
print("失败案例统计:")
for failure_type, count in failure_types.items():
print(f" {failure_type}: {count}")
return failure_types
def generate_evaluation_report(self, output_path='evaluation_report.txt'):
"""生成评估报告"""
print(f"\n生成评估报告: {output_path}")
# 运行全面评估
val_results = self.comprehensive_evaluation()
# 生成报告内容
report_content = f"""
# 模型评估报告
## 基础指标
- 模型: {self.model.ckpt_path}
- 数据集: {self.data_config}
- 评估时间: {pd.Timestamp.now()}
## 整体性能
- mAP@0.5: {val_results.results_dict.get('metrics/mAP50(B)', 0):.4f}
- mAP@0.5:0.95: {val_results.results_dict.get('metrics/mAP50-95(B)', 0):.4f}
- 精确率: {val_results.results_dict.get('metrics/precision(B)', 0):.4f}
- 召回率: {val_results.results_dict.get('metrics/recall(B)', 0):.4f}
## 推理性能
- 预处理时间: {val_results.speed.get('preprocess', 0):.2f}ms
- 推理时间: {val_results.speed.get('inference', 0):.2f}ms
- 后处理时间: {val_results.speed.get('postprocess', 0):.2f}ms
## 建议
基于评估结果,建议:
1. 如果精确率低,考虑提高置信度阈值
2. 如果召回率低,考虑降低置信度阈值或增加训练数据
3. 如果整体性能不佳,考虑使用更大的模型或改进数据质量
"""
# 保存报告
with open(output_path, 'w', encoding='utf-8') as f:
f.write(report_content)
print(f"评估报告已保存到: {output_path}")
# 使用示例
evaluator = ModelEvaluator(
model_path='runs/train/steel_defect_v1/weights/best.pt',
data_config='dataset.yaml'
)
# 运行全面评估
val_results = evaluator.comprehensive_evaluation()
# 生成评估报告
evaluator.generate_evaluation_report('model_evaluation_report.txt')通过以上完整的训练和评估流程,您可以系统地训练出高质量的YOLO缺陷检测模型。接下来的章节将介绍如何将训练好的模型部署到实际的生产环境中。
实际应用和部署指南
模型部署策略
训练完成的YOLO模型需要部署到实际的生产环境中才能发挥价值。不同的应用场景对部署方式有不同的要求,本节将详细介绍各种部署策略和实现方法。
部署环境分类
边缘设备部署
边缘设备部署是指将模型部署到生产线附近的边缘计算设备上,具有低延迟、数据安全性高的优势:
适用场景:
- 实时质量检测系统
- 生产线在线检测
- 离线环境或网络不稳定的场所
- 对数据隐私要求严格的应用
硬件要求:
- CPU:Intel i5以上或ARM Cortex-A78等高性能处理器
- GPU:NVIDIA Jetson系列、Intel Movidius或专用AI芯片
- 内存:8GB以上RAM
- 存储:64GB以上高速存储
优势:
- 响应速度快,延迟低
- 数据不需要上传到云端,安全性高
- 不依赖网络连接,稳定性好
- 可以进行实时决策和控制
挑战:
- 硬件成本相对较高
- 模型更新和维护相对复杂
- 计算资源有限,需要模型优化
云端部署
云端部署是指将模型部署到云服务器上,通过API接口提供服务:
适用场景:
- 批量图像处理
- 多地点统一检测服务
- 需要强大计算资源的复杂模型
- 快速原型验证和测试
优势:
- 计算资源丰富,可以使用大型模型
- 易于扩展和维护
- 成本相对较低(按需付费)
- 便于集中管理和监控
挑战:
- 网络延迟可能影响实时性
- 数据传输成本和安全性考虑
- 依赖网络连接的稳定性
混合部署
混合部署结合了边缘和云端的优势,在边缘设备进行实时检测,在云端进行模型训练和更新:
架构特点:
- 边缘设备负责实时推理
- 云端负责模型训练和版本管理
- 通过边缘-云协同实现最优性能
模型优化与加速
模型量化技术
模型量化是减少模型大小和提高推理速度的重要技术:
import torch
from ultralytics import YOLO
import onnx
import onnxruntime as ort
class ModelOptimizer:
"""模型优化器"""
def __init__(self, model_path):
self.model_path = model_path
self.model = YOLO(model_path)
def quantize_pytorch_model(self, calibration_data_path, output_path):
"""PyTorch模型量化"""
print("开始PyTorch模型量化...")
# 加载模型
model = torch.jit.load(self.model_path)
model.eval()
# 准备校准数据
calibration_dataset = self.prepare_calibration_data(calibration_data_path)
# 配置量化
quantized_model = torch.quantization.quantize_dynamic(
model,
{torch.nn.Linear, torch.nn.Conv2d},
dtype=torch.qint8
)
# 保存量化模型
torch.jit.save(quantized_model, output_path)
print(f"量化模型已保存到: {output_path}")
# 比较模型大小
original_size = os.path.getsize(self.model_path) / (1024 * 1024)
quantized_size = os.path.getsize(output_path) / (1024 * 1024)
compression_ratio = original_size / quantized_size
print(f"原始模型大小: {original_size:.2f} MB")
print(f"量化模型大小: {quantized_size:.2f} MB")
print(f"压缩比: {compression_ratio:.2f}x")
return quantized_model
def export_to_onnx(self, output_path, imgsz=640, dynamic=False):
"""导出为ONNX格式"""
print("导出ONNX模型...")
# 导出ONNX
onnx_path = self.model.export(
format='onnx',
imgsz=imgsz,
dynamic=dynamic,
simplify=True,
opset=11
)
# 验证ONNX模型
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print(f"ONNX模型已导出到: {onnx_path}")
return onnx_path
def optimize_onnx_model(self, onnx_path, optimized_path):
"""优化ONNX模型"""
import onnxoptimizer
print("优化ONNX模型...")
# 加载ONNX模型
model = onnx.load(onnx_path)
# 应用优化
optimized_model = onnxoptimizer.optimize(model, [
'eliminate_deadend',
'eliminate_identity',
'eliminate_nop_dropout',
'eliminate_nop_monotone_argmax',
'eliminate_nop_pad',
'eliminate_nop_transpose',
'eliminate_unused_initializer',
'extract_constant_to_initializer',
'fuse_add_bias_into_conv',
'fuse_bn_into_conv',
'fuse_consecutive_concats',
'fuse_consecutive_log_softmax',
'fuse_consecutive_reduce_unsqueeze',
'fuse_consecutive_squeezes',
'fuse_consecutive_transposes',
'fuse_matmul_add_bias_into_gemm',
'fuse_pad_into_conv',
'fuse_transpose_into_gemm',
'lift_lexical_references',
'nop',
'split_init',
'split_predict'
])
# 保存优化后的模型
onnx.save(optimized_model, optimized_path)
print(f"优化后的ONNX模型已保存到: {optimized_path}")
return optimized_path
def convert_to_tensorrt(self, onnx_path, engine_path, precision='fp16'):
"""转换为TensorRT引擎"""
try:
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
except ImportError:
print("TensorRT未安装,请先安装TensorRT")
return None
print(f"转换为TensorRT引擎 (精度: {precision})...")
# 创建TensorRT logger
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
# 创建builder
builder = trt.Builder(TRT_LOGGER)
config = builder.create_builder_config()
# 设置精度
if precision == 'fp16':
config.set_flag(trt.BuilderFlag.FP16)
elif precision == 'int8':
config.set_flag(trt.BuilderFlag.INT8)
# 需要设置校准器
# 解析ONNX模型
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
parser = trt.OnnxParser(network, TRT_LOGGER)
with open(onnx_path, 'rb') as model:
if not parser.parse(model.read()):
print("解析ONNX模型失败")
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
# 构建引擎
engine = builder.build_engine(network, config)
if engine is None:
print("构建TensorRT引擎失败")
return None
# 保存引擎
with open(engine_path, 'wb') as f:
f.write(engine.serialize())
print(f"TensorRT引擎已保存到: {engine_path}")
return engine_path
def benchmark_models(self, test_images_path, num_runs=100):
"""性能基准测试"""
import time
import cv2
import numpy as np
print("开始性能基准测试...")
# 准备测试图像
test_images = []
for img_path in Path(test_images_path).glob('*.jpg'):
img = cv2.imread(str(img_path))
img = cv2.resize(img, (640, 640))
test_images.append(img)
if not test_images:
print("未找到测试图像")
return
# 测试原始模型
print("测试原始PyTorch模型...")
pytorch_times = []
for _ in range(num_runs):
start_time = time.time()
for img in test_images:
results = self.model.predict(img, verbose=False)
end_time = time.time()
pytorch_times.append(end_time - start_time)
avg_pytorch_time = np.mean(pytorch_times) * 1000 # 转换为毫秒
print(f"PyTorch模型平均推理时间: {avg_pytorch_time:.2f} ms")
# 如果有ONNX模型,测试ONNX性能
onnx_path = self.model_path.replace('.pt', '.onnx')
if Path(onnx_path).exists():
print("测试ONNX模型...")
# 创建ONNX Runtime会话
ort_session = ort.InferenceSession(onnx_path)
onnx_times = []
for _ in range(num_runs):
start_time = time.time()
for img in test_images:
# 预处理图像
img_tensor = img.transpose(2, 0, 1).astype(np.float32) / 255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
# ONNX推理
ort_inputs = {ort_session.get_inputs()[0].name: img_tensor}
ort_outputs = ort_session.run(None, ort_inputs)
end_time = time.time()
onnx_times.append(end_time - start_time)
avg_onnx_time = np.mean(onnx_times) * 1000
speedup = avg_pytorch_time / avg_onnx_time
print(f"ONNX模型平均推理时间: {avg_onnx_time:.2f} ms")
print(f"ONNX加速比: {speedup:.2f}x")
return {
'pytorch_time': avg_pytorch_time,
'onnx_time': avg_onnx_time if 'avg_onnx_time' in locals() else None
}
# 使用示例
optimizer = ModelOptimizer('runs/train/steel_defect_v1/weights/best.pt')
# 导出ONNX模型
onnx_path = optimizer.export_to_onnx('model.onnx', imgsz=640)
# 优化ONNX模型
optimized_onnx = optimizer.optimize_onnx_model(onnx_path, 'model_optimized.onnx')
# 性能测试
benchmark_results = optimizer.benchmark_models('data/test/images')模型剪枝技术
模型剪枝通过移除不重要的参数来减少模型大小:
import torch
import torch.nn.utils.prune as prune
class ModelPruner:
"""模型剪枝器"""
def __init__(self, model):
self.model = model
def structured_pruning(self, pruning_ratio=0.3):
"""结构化剪枝"""
print(f"开始结构化剪枝 (剪枝比例: {pruning_ratio})")
# 获取所有卷积层
conv_layers = []
for module in self.model.modules():
if isinstance(module, torch.nn.Conv2d):
conv_layers.append(module)
# 对每个卷积层进行剪枝
for layer in conv_layers:
prune.ln_structured(
layer,
name='weight',
amount=pruning_ratio,
n=2,
dim=0
)
print("结构化剪枝完成")
return self.model
def unstructured_pruning(self, pruning_ratio=0.3):
"""非结构化剪枝"""
print(f"开始非结构化剪枝 (剪枝比例: {pruning_ratio})")
# 获取所有参数
parameters_to_prune = []
for module in self.model.modules():
if isinstance(module, (torch.nn.Conv2d, torch.nn.Linear)):
parameters_to_prune.append((module, 'weight'))
# 全局剪枝
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=pruning_ratio,
)
print("非结构化剪枝完成")
return self.model
def remove_pruning(self):
"""移除剪枝掩码,永久应用剪枝"""
for module in self.model.modules():
if isinstance(module, (torch.nn.Conv2d, torch.nn.Linear)):
try:
prune.remove(module, 'weight')
except ValueError:
pass # 该层没有被剪枝
print("剪枝掩码已移除")
return self.model
def calculate_sparsity(self):
"""计算模型稀疏度"""
total_params = 0
zero_params = 0
for module in self.model.modules():
if isinstance(module, (torch.nn.Conv2d, torch.nn.Linear)):
total_params += module.weight.numel()
zero_params += (module.weight == 0).sum().item()
sparsity = zero_params / total_params
print(f"模型稀疏度: {sparsity:.2%}")
return sparsity
# 使用示例
# pruner = ModelPruner(model)
# pruned_model = pruner.unstructured_pruning(pruning_ratio=0.3)
# sparsity = pruner.calculate_sparsity()实时检测应用开发
基于OpenCV的实时检测系统
import cv2
import numpy as np
from ultralytics import YOLO
import time
from collections import deque
import threading
import queue
class RealTimeDefectDetector:
"""实时缺陷检测系统"""
def __init__(self, model_path, conf_threshold=0.5, iou_threshold=0.45):
"""
初始化检测器
Args:
model_path: 模型文件路径
conf_threshold: 置信度阈值
iou_threshold: IoU阈值
"""
self.model = YOLO(model_path)
self.conf_threshold = conf_threshold
self.iou_threshold = iou_threshold
# 性能监控
self.fps_queue = deque(maxlen=30)
self.detection_count = 0
self.total_processing_time = 0
# 结果缓存
self.result_queue = queue.Queue(maxsize=10)
# 类别颜色映射
self.colors = self.generate_colors(len(self.model.names))
def generate_colors(self, num_classes):
"""生成类别颜色"""
colors = []
for i in range(num_classes):
hue = i * 180 // num_classes
color = cv2.cvtColor(np.uint8([[[hue, 255, 255]]]), cv2.COLOR_HSV2BGR)[0][0]
colors.append([int(c) for c in color])
return colors
def preprocess_image(self, image):
"""图像预处理"""
# 保存原始尺寸
original_shape = image.shape[:2]
# 调整尺寸
processed_image = cv2.resize(image, (640, 640))
return processed_image, original_shape
def detect_defects(self, image):
"""检测缺陷"""
start_time = time.time()
# 预处理
processed_image, original_shape = self.preprocess_image(image)
# 模型推理
results = self.model.predict(
processed_image,
conf=self.conf_threshold,
iou=self.iou_threshold,
verbose=False
)
# 后处理
detections = self.postprocess_results(results[0], original_shape)
# 更新性能统计
processing_time = time.time() - start_time
self.update_performance_stats(processing_time)
return detections
def postprocess_results(self, result, original_shape):
"""后处理检测结果"""
detections = []
if result.boxes is not None:
boxes = result.boxes.xyxy.cpu().numpy()
confidences = result.boxes.conf.cpu().numpy()
class_ids = result.boxes.cls.cpu().numpy().astype(int)
# 缩放坐标到原始图像尺寸
scale_x = original_shape[1] / 640
scale_y = original_shape[0] / 640
for box, conf, class_id in zip(boxes, confidences, class_ids):
x1, y1, x2, y2 = box
# 缩放坐标
x1 = int(x1 * scale_x)
y1 = int(y1 * scale_y)
x2 = int(x2 * scale_x)
y2 = int(y2 * scale_y)
detection = {
'bbox': [x1, y1, x2, y2],
'confidence': float(conf),
'class_id': int(class_id),
'class_name': self.model.names[class_id]
}
detections.append(detection)
return detections
def draw_detections(self, image, detections):
"""绘制检测结果"""
annotated_image = image.copy()
for detection in detections:
x1, y1, x2, y2 = detection['bbox']
confidence = detection['confidence']
class_id = detection['class_id']
class_name = detection['class_name']
# 获取颜色
color = self.colors[class_id]
# 绘制边界框
cv2.rectangle(annotated_image, (x1, y1), (x2, y2), color, 2)
# 绘制标签
label = f"{class_name}: {confidence:.2f}"
label_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)[0]
# 标签背景
cv2.rectangle(
annotated_image,
(x1, y1 - label_size[1] - 10),
(x1 + label_size[0], y1),
color,
-1
)
# 标签文字
cv2.putText(
annotated_image,
label,
(x1, y1 - 5),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(255, 255, 255),
2
)
return annotated_image
def draw_performance_info(self, image):
"""绘制性能信息"""
# 计算FPS
current_fps = len(self.fps_queue) / sum(self.fps_queue) if self.fps_queue else 0
# 计算平均处理时间
avg_processing_time = (self.total_processing_time / self.detection_count * 1000
if self.detection_count > 0 else 0)
# 绘制信息
info_text = [
f"FPS: {current_fps:.1f}",
f"Processing: {avg_processing_time:.1f}ms",
f"Detections: {self.detection_count}",
f"Conf: {self.conf_threshold:.2f}"
]
y_offset = 30
for text in info_text:
cv2.putText(
image,
text,
(10, y_offset),
cv2.FONT_HERSHEY_SIMPLEX,
0.6,
(0, 255, 0),
2
)
y_offset += 25
return image
def update_performance_stats(self, processing_time):
"""更新性能统计"""
self.fps_queue.append(processing_time)
self.detection_count += 1
self.total_processing_time += processing_time
def run_camera_detection(self, camera_id=0, save_video=False, output_path='output.mp4'):
"""运行摄像头实时检测"""
print(f"启动摄像头检测 (设备ID: {camera_id})")
# 初始化摄像头
cap = cv2.VideoCapture(camera_id)
if not cap.isOpened():
print(f"无法打开摄像头 {camera_id}")
return
# 设置摄像头参数
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
cap.set(cv2.CAP_PROP_FPS, 30)
# 视频录制设置
if save_video:
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
video_writer = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
print("按 'q' 退出,按 's' 保存当前帧,按 '+'/'-' 调整置信度阈值")
frame_count = 0
try:
while True:
ret, frame = cap.read()
if not ret:
print("无法读取摄像头帧")
break
frame_count += 1
# 检测缺陷
detections = self.detect_defects(frame)
# 绘制检测结果
annotated_frame = self.draw_detections(frame, detections)
# 绘制性能信息
annotated_frame = self.draw_performance_info(annotated_frame)
# 显示结果
cv2.imshow('Defect Detection', annotated_frame)
# 保存视频
if save_video:
video_writer.write(annotated_frame)
# 处理按键
key = cv2.waitKey(1) & 0xFF
if key == ord('q'):
break
elif key == ord('s'):
# 保存当前帧
save_path = f'detection_frame_{frame_count}.jpg'
cv2.imwrite(save_path, annotated_frame)
print(f"帧已保存到: {save_path}")
elif key == ord('+') or key == ord('='):
# 增加置信度阈值
self.conf_threshold = min(0.95, self.conf_threshold + 0.05)
print(f"置信度阈值: {self.conf_threshold:.2f}")
elif key == ord('-'):
# 减少置信度阈值
self.conf_threshold = max(0.05, self.conf_threshold - 0.05)
print(f"置信度阈值: {self.conf_threshold:.2f}")
except KeyboardInterrupt:
print("检测被用户中断")
finally:
# 清理资源
cap.release()
if save_video:
video_writer.release()
cv2.destroyAllWindows()
# 打印最终统计
print(f"\n检测统计:")
print(f"总帧数: {frame_count}")
print(f"总检测数: {self.detection_count}")
print(f"平均FPS: {len(self.fps_queue) / sum(self.fps_queue) if self.fps_queue else 0:.1f}")
def run_video_detection(self, video_path, output_path=None):
"""运行视频文件检测"""
print(f"开始处理视频: {video_path}")
# 打开视频文件
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"无法打开视频文件: {video_path}")
return
# 获取视频信息
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(f"视频信息: {width}x{height}, {fps:.1f} FPS, {total_frames} 帧")
# 设置输出视频
if output_path:
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
frame_count = 0
try:
while True:
ret, frame = cap.read()
if not ret:
break
frame_count += 1
# 显示进度
if frame_count % 30 == 0:
progress = frame_count / total_frames * 100
print(f"处理进度: {progress:.1f}% ({frame_count}/{total_frames})")
# 检测缺陷
detections = self.detect_defects(frame)
# 绘制检测结果
annotated_frame = self.draw_detections(frame, detections)
# 绘制性能信息
annotated_frame = self.draw_performance_info(annotated_frame)
# 保存输出视频
if output_path:
video_writer.write(annotated_frame)
# 显示结果(可选)
cv2.imshow('Video Detection', annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
except KeyboardInterrupt:
print("处理被用户中断")
finally:
# 清理资源
cap.release()
if output_path:
video_writer.release()
cv2.destroyAllWindows()
print(f"视频处理完成: {frame_count}/{total_frames} 帧")
if output_path:
print(f"输出视频已保存到: {output_path}")
# 使用示例
def main():
"""主函数"""
# 创建检测器
detector = RealTimeDefectDetector(
model_path='runs/train/steel_defect_v1/weights/best.pt',
conf_threshold=0.5,
iou_threshold=0.45
)
# 选择检测模式
mode = input("选择检测模式 (1: 摄像头, 2: 视频文件): ")
if mode == '1':
# 摄像头实时检测
camera_id = int(input("输入摄像头ID (默认0): ") or "0")
save_video = input("是否保存视频? (y/n): ").lower() == 'y'
detector.run_camera_detection(
camera_id=camera_id,
save_video=save_video,
output_path='realtime_detection.mp4' if save_video else None
)
elif mode == '2':
# 视频文件检测
video_path = input("输入视频文件路径: ")
output_path = input("输入输出路径 (可选): ") or None
detector.run_video_detection(video_path, output_path)
else:
print("无效的模式选择")
if __name__ == "__main__":
main()Web应用开发
基于Flask的Web检测服务
from flask import Flask, request, jsonify, render_template, send_file
from werkzeug.utils import secure_filename
import os
import cv2
import numpy as np
from ultralytics import YOLO
import base64
import io
from PIL import Image
import json
from datetime import datetime
import sqlite3
import threading
app = Flask(__name__)
app.config['UPLOAD_FOLDER'] = 'uploads'
app.config['RESULT_FOLDER'] = 'results'
app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024 # 16MB max file size
# 确保目录存在
os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True)
os.makedirs(app.config['RESULT_FOLDER'], exist_ok=True)
class DefectDetectionService:
"""缺陷检测服务"""
def __init__(self, model_path):
self.model = YOLO(model_path)
self.detection_history = []
self.lock = threading.Lock()
# 初始化数据库
self.init_database()
def init_database(self):
"""初始化数据库"""
conn = sqlite3.connect('detection_history.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS detections (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT,
filename TEXT,
num_defects INTEGER,
defect_types TEXT,
confidence_avg REAL,
processing_time REAL
)
''')
conn.commit()
conn.close()
def detect_defects(self, image_path, conf_threshold=0.5):
"""检测图像中的缺陷"""
start_time = datetime.now()
# 加载图像
image = cv2.imread(image_path)
if image is None:
raise ValueError("无法加载图像")
# 模型推理
results = self.model.predict(
image,
conf=conf_threshold,
verbose=False
)
# 处理结果
detections = []
if results[0].boxes is not None:
boxes = results[0].boxes.xyxy.cpu().numpy()
confidences = results[0].boxes.conf.cpu().numpy()
class_ids = results[0].boxes.cls.cpu().numpy().astype(int)
for box, conf, class_id in zip(boxes, confidences, class_ids):
x1, y1, x2, y2 = box
detection = {
'bbox': [int(x1), int(y1), int(x2), int(y2)],
'confidence': float(conf),
'class_id': int(class_id),
'class_name': self.model.names[class_id]
}
detections.append(detection)
# 计算处理时间
processing_time = (datetime.now() - start_time).total_seconds()
# 保存检测历史
self.save_detection_history(
filename=os.path.basename(image_path),
detections=detections,
processing_time=processing_time
)
return detections, processing_time
def save_detection_history(self, filename, detections, processing_time):
"""保存检测历史"""
with self.lock:
conn = sqlite3.connect('detection_history.db')
cursor = conn.cursor()
# 计算统计信息
num_defects = len(detections)
defect_types = list(set([d['class_name'] for d in detections]))
confidence_avg = np.mean([d['confidence'] for d in detections]) if detections else 0
cursor.execute('''
INSERT INTO detections
(timestamp, filename, num_defects, defect_types, confidence_avg, processing_time)
VALUES (?, ?, ?, ?, ?, ?)
''', (
datetime.now().isoformat(),
filename,
num_defects,
json.dumps(defect_types),
confidence_avg,
processing_time
))
conn.commit()
conn.close()
def get_detection_history(self, limit=100):
"""获取检测历史"""
conn = sqlite3.connect('detection_history.db')
cursor = conn.cursor()
cursor.execute('''
SELECT * FROM detections
ORDER BY timestamp DESC
LIMIT ?
''', (limit,))
rows = cursor.fetchall()
conn.close()
history = []
for row in rows:
history.append({
'id': row[0],
'timestamp': row[1],
'filename': row[2],
'num_defects': row[3],
'defect_types': json.loads(row[4]),
'confidence_avg': row[5],
'processing_time': row[6]
})
return history
def get_statistics(self):
"""获取统计信息"""
conn = sqlite3.connect('detection_history.db')
cursor = conn.cursor()
# 总检测数
cursor.execute('SELECT COUNT(*) FROM detections')
total_detections = cursor.fetchone()[0]
# 总缺陷数
cursor.execute('SELECT SUM(num_defects) FROM detections')
total_defects = cursor.fetchone()[0] or 0
# 平均处理时间
cursor.execute('SELECT AVG(processing_time) FROM detections')
avg_processing_time = cursor.fetchone()[0] or 0
# 最常见的缺陷类型
cursor.execute('SELECT defect_types FROM detections WHERE num_defects > 0')
all_defect_types = []
for row in cursor.fetchall():
all_defect_types.extend(json.loads(row[0]))
defect_type_counts = {}
for defect_type in all_defect_types:
defect_type_counts[defect_type] = defect_type_counts.get(defect_type, 0) + 1
conn.close()
return {
'total_detections': total_detections,
'total_defects': total_defects,
'avg_processing_time': avg_processing_time,
'defect_type_counts': defect_type_counts
}
# 初始化检测服务
detection_service = DefectDetectionService('runs/train/steel_defect_v1/weights/best.pt')
@app.route('/')
def index():
"""主页"""
return render_template('index.html')
@app.route('/api/detect', methods=['POST'])
def api_detect():
"""API检测接口"""
try:
# 检查文件
if 'file' not in request.files:
return jsonify({'error': '未找到文件'}), 400
file = request.files['file']
if file.filename == '':
return jsonify({'error': '未选择文件'}), 400
# 获取参数
conf_threshold = float(request.form.get('confidence', 0.5))
# 保存文件
filename = secure_filename(file.filename)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
filename = f"{timestamp}_{filename}"
filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)
file.save(filepath)
# 检测缺陷
detections, processing_time = detection_service.detect_defects(
filepath, conf_threshold
)
# 生成结果图像
result_image_path = generate_result_image(filepath, detections)
# 返回结果
return jsonify({
'success': True,
'detections': detections,
'num_defects': len(detections),
'processing_time': processing_time,
'result_image': f'/api/result_image/{os.path.basename(result_image_path)}'
})
except Exception as e:
return jsonify({'error': str(e)}), 500
@app.route('/api/result_image/<filename>')
def api_result_image(filename):
"""获取结果图像"""
return send_file(
os.path.join(app.config['RESULT_FOLDER'], filename),
mimetype='image/jpeg'
)
@app.route('/api/history')
def api_history():
"""获取检测历史"""
limit = int(request.args.get('limit', 100))
history = detection_service.get_detection_history(limit)
return jsonify({
'success': True,
'history': history
})
@app.route('/api/statistics')
def api_statistics():
"""获取统计信息"""
stats = detection_service.get_statistics()
return jsonify({
'success': True,
'statistics': stats
})
def generate_result_image(image_path, detections):
"""生成结果图像"""
# 加载图像
image = cv2.imread(image_path)
# 定义颜色
colors = [
(0, 255, 0), # 绿色
(255, 0, 0), # 蓝色
(0, 0, 255), # 红色
(255, 255, 0), # 青色
(255, 0, 255), # 品红色
(0, 255, 255), # 黄色
]
# 绘制检测结果
for i, detection in enumerate(detections):
x1, y1, x2, y2 = detection['bbox']
confidence = detection['confidence']
class_name = detection['class_name']
# 选择颜色
color = colors[detection['class_id'] % len(colors)]
# 绘制边界框
cv2.rectangle(image, (x1, y1), (x2, y2), color, 2)
# 绘制标签
label = f"{class_name}: {confidence:.2f}"
label_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 2)[0]
# 标签背景
cv2.rectangle(
image,
(x1, y1 - label_size[1] - 10),
(x1 + label_size[0], y1),
color,
-1
)
# 标签文字
cv2.putText(
image,
label,
(x1, y1 - 5),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
(255, 255, 255),
2
)
# 保存结果图像
result_filename = f"result_{os.path.basename(image_path)}"
result_path = os.path.join(app.config['RESULT_FOLDER'], result_filename)
cv2.imwrite(result_path, image)
return result_path
# HTML模板
index_template = '''
<!DOCTYPE html>
<html>
<head>
<title>缺陷检测系统</title>
<meta charset="utf-8">
<style>
body { font-family: Arial, sans-serif; margin: 40px; }
.container { max-width: 800px; margin: 0 auto; }
.upload-area {
border: 2px dashed #ccc;
padding: 40px;
text-align: center;
margin: 20px 0;
}
.result { margin: 20px 0; padding: 20px; border: 1px solid #ddd; }
.detection-item {
background: #f5f5f5;
padding: 10px;
margin: 5px 0;
border-radius: 5px;
}
button {
background: #007bff;
color: white;
padding: 10px 20px;
border: none;
border-radius: 5px;
cursor: pointer;
}
button:hover { background: #0056b3; }
.stats { display: flex; justify-content: space-around; margin: 20px 0; }
.stat-item { text-align: center; }
</style>
</head>
<body>
<div class="container">
<h1>YOLO缺陷检测系统</h1>
<div class="upload-area" onclick="document.getElementById('fileInput').click()">
<p>点击选择图像文件或拖拽文件到此处</p>
<input type="file" id="fileInput" accept="image/*" style="display: none;">
</div>
<div>
<label>置信度阈值: </label>
<input type="range" id="confidence" min="0.1" max="0.9" step="0.1" value="0.5">
<span id="confidenceValue">0.5</span>
</div>
<button onclick="detectDefects()">开始检测</button>
<div id="result" class="result" style="display: none;">
<h3>检测结果</h3>
<div id="resultContent"></div>
</div>
<div id="statistics">
<h3>系统统计</h3>
<div class="stats" id="statsContent"></div>
</div>
</div>
<script>
// 更新置信度显示
document.getElementById('confidence').addEventListener('input', function() {
document.getElementById('confidenceValue').textContent = this.value;
});
// 文件选择处理
document.getElementById('fileInput').addEventListener('change', function() {
if (this.files.length > 0) {
document.querySelector('.upload-area p').textContent =
'已选择文件: ' + this.files[0].name;
}
});
// 检测缺陷
function detectDefects() {
const fileInput = document.getElementById('fileInput');
const confidence = document.getElementById('confidence').value;
if (!fileInput.files.length) {
alert('请先选择图像文件');
return;
}
const formData = new FormData();
formData.append('file', fileInput.files[0]);
formData.append('confidence', confidence);
// 显示加载状态
document.getElementById('resultContent').innerHTML = '检测中...';
document.getElementById('result').style.display = 'block';
fetch('/api/detect', {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => {
if (data.success) {
displayResults(data);
} else {
alert('检测失败: ' + data.error);
}
})
.catch(error => {
alert('请求失败: ' + error);
});
}
// 显示结果
function displayResults(data) {
let html = `
<p><strong>检测到 ${data.num_defects} 个缺陷</strong></p>
<p>处理时间: ${data.processing_time.toFixed(3)} 秒</p>
<img src="${data.result_image}" style="max-width: 100%; margin: 10px 0;">
<h4>缺陷详情:</h4>
`;
data.detections.forEach((detection, index) => {
html += `
<div class="detection-item">
<strong>${detection.class_name}</strong>
(置信度: ${detection.confidence.toFixed(3)})
<br>位置: [${detection.bbox.join(', ')}]
</div>
`;
});
document.getElementById('resultContent').innerHTML = html;
// 更新统计信息
loadStatistics();
}
// 加载统计信息
function loadStatistics() {
fetch('/api/statistics')
.then(response => response.json())
.then(data => {
if (data.success) {
const stats = data.statistics;
document.getElementById('statsContent').innerHTML = `
<div class="stat-item">
<h4>${stats.total_detections}</h4>
<p>总检测数</p>
</div>
<div class="stat-item">
<h4>${stats.total_defects}</h4>
<p>总缺陷数</p>
</div>
<div class="stat-item">
<h4>${stats.avg_processing_time.toFixed(3)}s</h4>
<p>平均处理时间</p>
</div>
`;
}
});
}
// 页面加载时获取统计信息
window.onload = function() {
loadStatistics();
};
</script>
</body>
</html>
'''
# 创建模板目录和文件
os.makedirs('templates', exist_ok=True)
with open('templates/index.html', 'w', encoding='utf-8') as f:
f.write(index_template)
if __name__ == '__main__':
print("启动Web检测服务...")
print("访问地址: http://localhost:5000")
app.run(debug=True, host='0.0.0.0', port=5000)通过以上完整的实际应用和部署指南,您可以将训练好的YOLO模型成功部署到各种实际环境中,实现真正的缺陷检测应用。
总结与最佳实践
项目开发流程总结
通过本指南的学习,您已经掌握了使用YOLO进行缺陷检测的完整流程。让我们回顾一下整个项目开发的关键步骤和最佳实践。
项目规划阶段
在开始任何YOLO缺陷检测项目之前,充分的规划是成功的基础。项目规划应该包括明确的目标定义、需求分析和可行性评估。
目标定义的重要性:明确定义项目目标是第一步,这包括确定要检测的缺陷类型、精度要求、实时性需求和部署环境。不同的应用场景对模型的要求差异很大,例如,生产线实时检测需要高速度,而质量审核可能更注重高精度。
数据需求评估:评估数据的可获得性和质量是项目成功的关键。需要考虑数据的数量、质量、多样性和标注成本。如果现有数据不足,需要制定数据收集计划,包括数据采集设备、采集环境和采集策略。
技术可行性分析:评估技术方案的可行性,包括硬件资源、软件环境、开发周期和维护成本。对于资源有限的项目,可能需要考虑使用较小的模型或云端部署方案。
数据准备阶段
数据质量直接决定了模型的性能上限,因此数据准备阶段需要格外重视。
数据收集策略:制定系统性的数据收集策略,确保数据的代表性和多样性。数据应该覆盖不同的光照条件、拍摄角度、缺陷严重程度和背景环境。对于工业应用,还需要考虑不同批次、不同设备和不同操作员的影响。
标注质量控制:建立严格的标注质量控制流程,包括标注标准制定、标注员培训、质量检查和一致性验证。可以采用多人标注、交叉验证和专家审核等方法来提高标注质量。
数据增强策略:根据具体应用场景设计合适的数据增强策略。对于缺陷检测,几何变换(旋转、翻转、缩放)通常很有效,而颜色变换需要谨慎使用,避免改变缺陷的本质特征。
模型训练阶段
模型训练是整个项目的核心环节,需要系统性的方法和持续的优化。
基线模型建立:首先建立一个简单的基线模型,使用默认参数进行训练,获得初始性能指标。这个基线模型为后续优化提供参考点,也有助于快速发现数据或环境配置问题。
迭代优化策略:采用迭代优化的方法,每次只调整一个或少数几个参数,观察其对性能的影响。建议的优化顺序是:数据质量 → 模型架构 → 超参数 → 训练策略。
实验管理:建立完善的实验管理系统,记录每次实验的参数设置、性能指标和观察结果。可以使用Weights & Biases、TensorBoard或简单的Excel表格来管理实验记录。
性能监控:在训练过程中持续监控模型性能,及时发现过拟合、欠拟合或训练不稳定等问题。设置合理的早停策略,避免过度训练。
模型评估阶段
全面的模型评估确保模型在实际应用中的可靠性。
多维度评估:不仅要关注整体的mAP指标,还要分析各个类别的性能、不同尺寸目标的检测效果、以及在不同条件下的鲁棒性。
错误分析:深入分析模型的错误案例,识别模型的弱点和改进方向。常见的错误类型包括误检、漏检、类别混淆和定位不准确。
实际场景测试:在真实的应用环境中测试模型性能,验证模型在实际条件下的表现。实验室环境和实际环境往往存在差异,需要在实际环境中进行充分验证。
部署实施阶段
成功的部署需要考虑技术、运维和业务等多个方面。
部署方案选择:根据应用需求选择合适的部署方案,包括硬件平台、软件架构和网络配置。需要平衡性能、成本、可维护性和可扩展性等因素。
系统集成:将检测模型集成到现有的生产系统中,确保与其他系统的兼容性和数据流的顺畅。可能需要开发API接口、数据库连接和用户界面等组件。
运维监控:建立完善的运维监控系统,实时监控模型性能、系统状态和业务指标。设置告警机制,及时发现和处理异常情况。
性能优化最佳实践
模型选择策略
选择合适的模型是性能优化的第一步。不同的应用场景需要不同的模型配置。
精度优先场景:对于质量要求极高的应用,如医疗器械检测或航空航天部件检测,应该选择较大的模型(如YOLOv8l或YOLOv8x),并使用更长的训练时间和更精细的超参数调优。
速度优先场景:对于实时性要求很高的应用,如生产线在线检测,应该选择较小的模型(如YOLOv8n或YOLOv8s),并考虑使用模型量化、剪枝等优化技术。
平衡场景:对于大多数工业应用,YOLOv8s或YOLOv8m提供了精度和速度的良好平衡,是推荐的起始选择。
数据优化策略
数据质量的提升往往比模型复杂度的增加更有效。
数据清洗:定期检查和清理训练数据,移除质量差的图像、错误的标注和重复的样本。建立数据质量评估标准,持续改进数据质量。
难样本挖掘:识别和收集模型表现较差的难样本,增加这些样本在训练数据中的比例。可以使用主动学习的方法,让模型自动识别需要更多训练的样本。
数据平衡:确保各个类别的样本数量相对平衡,避免某些类别的样本过少导致模型偏向。可以使用重采样、数据增强或损失函数权重调整等方法来处理数据不平衡问题。
训练优化策略
学习率调度:使用合适的学习率调度策略,如余弦退火、阶梯衰减或自适应学习率。学习率的选择对训练效果有重要影响,需要根据具体情况进行调整。
批次大小优化:选择合适的批次大小,平衡训练稳定性和内存使用。较大的批次大小通常提供更稳定的梯度,但需要更多的内存。可以使用梯度累积技术在有限内存下模拟大批次训练。
正则化技术:使用适当的正则化技术防止过拟合,包括权重衰减、Dropout、数据增强和早停等。正则化的强度需要根据数据量和模型复杂度进行调整。
推理优化策略
模型量化:使用INT8量化可以显著减少模型大小和推理时间,通常只会带来很小的精度损失。对于边缘设备部署,量化是必要的优化手段。
模型剪枝:移除不重要的网络连接或通道,减少计算量。结构化剪枝更容易在硬件上加速,而非结构化剪枝可以获得更高的压缩比。
推理引擎优化:使用专门的推理引擎,如TensorRT、ONNX Runtime或OpenVINO,可以显著提高推理速度。这些引擎针对特定硬件进行了优化,能够充分利用硬件性能。
常见问题解答
Q1: 训练过程中损失不下降怎么办?
A: 损失不下降可能有多种原因:
学习率问题:学习率过小会导致收敛缓慢,学习率过大会导致训练不稳定。建议从较大的学习率开始,观察损失变化,然后逐步调整。
数据问题:检查数据质量,确保标注正确、图像清晰、类别平衡。错误的标注会严重影响训练效果。
模型问题:检查模型配置是否正确,特别是类别数量、输入尺寸等参数。
环境问题:确保CUDA、PyTorch等环境配置正确,GPU内存充足。
Q2: 模型在验证集上表现好,但在测试集上表现差怎么办?
A: 这通常是过拟合的表现:
增加正则化:使用更强的数据增强、增加权重衰减、使用Dropout等。
减少模型复杂度:使用较小的模型或减少训练轮数。
增加训练数据:收集更多的训练数据,特别是与测试集分布相似的数据。
检查数据分布:确保训练集、验证集和测试集的数据分布一致。
Q3: 如何处理小目标检测效果差的问题?
A: 小目标检测是YOLO的传统弱项,可以采用以下策略:
多尺度训练:使用不同尺寸的输入图像进行训练,提高模型对不同尺度的适应性。
数据增强:使用Mosaic、MixUp等增强技术,增加小目标的训练样本。
网络结构优化:使用FPN、PANet等特征融合结构,改善小目标的特征表达。
后处理优化:调整NMS阈值、置信度阈值等参数,优化小目标的检测效果。
Q4: 如何提高模型的推理速度?
A: 提高推理速度的方法包括:
模型优化:使用较小的模型、模型量化、模型剪枝等技术。
输入优化:减少输入图像尺寸、使用更高效的预处理方法。
硬件优化:使用GPU、专用AI芯片或优化的推理引擎。
软件优化:使用TensorRT、ONNX Runtime等推理加速库。
Q5: 如何处理类别不平衡问题?
A: 类别不平衡是缺陷检测中的常见问题:
数据层面:使用重采样、数据增强等方法平衡各类别样本数量。
损失函数:使用Focal Loss、加权交叉熵等损失函数,增加少数类别的权重。
评估指标:使用F1分数、平衡准确率等对不平衡数据更敏感的指标。
后处理:调整不同类别的置信度阈值,平衡精确率和召回率。
Q6: 如何选择合适的数据增强策略?
A: 数据增强策略的选择需要考虑具体应用:
几何变换:旋转、翻转、缩放等通常是安全的选择,不会改变缺陷的本质特征。
颜色变换:需要谨慎使用,确保不会改变缺陷的视觉特征。对于依赖颜色特征的缺陷检测,应该避免过强的颜色变换。
噪声添加:适量的噪声可以提高模型鲁棒性,但过多的噪声会影响训练效果。
高级技术:Mosaic、MixUp、CutMix等技术通常能够显著提高性能,特别是对小目标检测。
Q7: 如何评估模型在实际应用中的性能?
A: 实际应用中的性能评估需要考虑多个维度:
准确性指标:mAP、精确率、召回率、F1分数等传统指标。
速度指标:推理时间、FPS、延迟等性能指标。
鲁棒性指标:在不同光照、角度、距离等条件下的性能稳定性。
业务指标:误检率、漏检率对实际业务的影响,成本效益分析等。
Q8: 如何持续改进已部署的模型?
A: 模型的持续改进是一个长期过程:
数据收集:持续收集新的数据,特别是模型表现不佳的案例。
性能监控:建立监控系统,跟踪模型在生产环境中的性能变化。
定期重训练:根据新数据定期重新训练模型,保持模型的时效性。
A/B测试:使用A/B测试比较不同模型版本的性能,确保改进的有效性。
附录
代码示例汇总
本节汇总了指南中的主要代码示例,方便读者查阅和使用。
完整的训练脚本
#!/usr/bin/env python3
"""
YOLO缺陷检测完整训练脚本
作者: Manus AI
版本: 1.0
"""
import os
import yaml
import torch
from ultralytics import YOLO
from pathlib import Path
import argparse
import logging
# 设置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def setup_environment():
"""设置训练环境"""
# 检查CUDA
if torch.cuda.is_available():
logger.info(f"CUDA可用,GPU数量: {torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
logger.info(f"GPU {i}: {torch.cuda.get_device_name(i)}")
else:
logger.warning("CUDA不可用,将使用CPU训练")
# 创建必要目录
os.makedirs('runs/train', exist_ok=True)
os.makedirs('data', exist_ok=True)
def create_dataset_config(data_path, class_names, output_path='dataset.yaml'):
"""创建数据集配置文件"""
config = {
'path': str(Path(data_path).absolute()),
'train': 'train/images',
'val': 'val/images',
'test': 'test/images',
'nc': len(class_names),
'names': {i: name for i, name in enumerate(class_names)}
}
with open(output_path, 'w') as f:
yaml.dump(config, f, default_flow_style=False)
logger.info(f"数据集配置已保存到: {output_path}")
return output_path
def train_model(config_path, model_name='yolov8s.pt', **kwargs):
"""训练YOLO模型"""
# 默认训练参数
default_params = {
'epochs': 100,
'imgsz': 640,
'batch': 16,
'lr0': 0.01,
'weight_decay': 0.0005,
'warmup_epochs': 3,
'patience': 50,
'save_period': 10,
'device': 'auto',
'workers': 8,
'project': 'runs/train',
'name': 'defect_detection',
'verbose': True,
'seed': 42
}
# 更新参数
default_params.update(kwargs)
# 加载模型
model = YOLO(model_name)
# 开始训练
logger.info("开始训练...")
results = model.train(data=config_path, **default_params)
logger.info("训练完成!")
return results
def main():
"""主函数"""
parser = argparse.ArgumentParser(description='YOLO缺陷检测训练脚本')
parser.add_argument('--data', type=str, required=True, help='数据集路径')
parser.add_argument('--model', type=str, default='yolov8s.pt', help='模型名称')
parser.add_argument('--epochs', type=int, default=100, help='训练轮数')
parser.add_argument('--batch', type=int, default=16, help='批次大小')
parser.add_argument('--imgsz', type=int, default=640, help='图像尺寸')
parser.add_argument('--lr0', type=float, default=0.01, help='初始学习率')
parser.add_argument('--name', type=str, default='defect_detection', help='实验名称')
args = parser.parse_args()
# 设置环境
setup_environment()
# 类别名称(根据实际情况修改)
class_names = [
'rolled-in_scale', 'patches', 'crazing',
'pitted_surface', 'inclusion', 'scratches'
]
# 创建数据集配置
config_path = create_dataset_config(args.data, class_names)
# 训练模型
results = train_model(
config_path=config_path,
model_name=args.model,
epochs=args.epochs,
batch=args.batch,
imgsz=args.imgsz,
lr0=args.lr0,
name=args.name
)
logger.info(f"训练结果已保存到: {results.save_dir}")
if __name__ == "__main__":
main()数据预处理工具
#!/usr/bin/env python3
"""
数据预处理工具集
"""
import cv2
import numpy as np
from pathlib import Path
import json
import xml.etree.ElementTree as ET
from sklearn.model_selection import train_test_split
import shutil
import argparse
class DataProcessor:
"""数据处理器"""
def __init__(self, input_dir, output_dir):
self.input_dir = Path(input_dir)
self.output_dir = Path(output_dir)
self.output_dir.mkdir(parents=True, exist_ok=True)
def convert_voc_to_yolo(self, class_names):
"""转换VOC格式到YOLO格式"""
class_to_id = {name: idx for idx, name in enumerate(class_names)}
for xml_file in self.input_dir.glob('**/*.xml'):
# 解析XML
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像尺寸
size = root.find('size')
img_width = int(size.find('width').text)
img_height = int(size.find('height').text)
# 转换标注
yolo_annotations = []
for obj in root.findall('object'):
class_name = obj.find('name').text
if class_name not in class_to_id:
continue
class_id = class_to_id[class_name]
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
# 转换为YOLO格式
center_x = (xmin + xmax) / 2.0 / img_width
center_y = (ymin + ymax) / 2.0 / img_height
width = (xmax - xmin) / img_width
height = (ymax - ymin) / img_height
yolo_annotations.append(
f"{class_id} {center_x:.6f} {center_y:.6f} {width:.6f} {height:.6f}"
)
# 保存YOLO格式标注
txt_file = self.output_dir / f"{xml_file.stem}.txt"
with open(txt_file, 'w') as f:
f.write('\n'.join(yolo_annotations))
def split_dataset(self, train_ratio=0.7, val_ratio=0.15, test_ratio=0.15):
"""划分数据集"""
# 收集所有图像文件
image_files = []
for ext in ['*.jpg', '*.jpeg', '*.png', '*.bmp']:
image_files.extend(self.input_dir.glob(f"**/{ext}"))
# 划分数据
train_files, temp_files = train_test_split(
image_files, test_size=(1-train_ratio), random_state=42
)
val_files, test_files = train_test_split(
temp_files, test_size=(test_ratio/(val_ratio+test_ratio)), random_state=42
)
# 创建目录结构
for split in ['train', 'val', 'test']:
(self.output_dir / split / 'images').mkdir(parents=True, exist_ok=True)
(self.output_dir / split / 'labels').mkdir(parents=True, exist_ok=True)
# 复制文件
splits = {'train': train_files, 'val': val_files, 'test': test_files}
for split_name, files in splits.items():
for img_file in files:
# 复制图像
dst_img = self.output_dir / split_name / 'images' / img_file.name
shutil.copy2(img_file, dst_img)
# 复制标注
label_file = img_file.with_suffix('.txt')
if label_file.exists():
dst_label = self.output_dir / split_name / 'labels' / label_file.name
shutil.copy2(label_file, dst_label)
print(f"数据集划分完成:")
print(f"训练集: {len(train_files)} 张")
print(f"验证集: {len(val_files)} 张")
print(f"测试集: {len(test_files)} 张")
def main():
parser = argparse.ArgumentParser(description='数据预处理工具')
parser.add_argument('--input', type=str, required=True, help='输入目录')
parser.add_argument('--output', type=str, required=True, help='输出目录')
parser.add_argument('--format', type=str, choices=['voc', 'coco'], default='voc', help='输入格式')
parser.add_argument('--classes', type=str, nargs='+', required=True, help='类别名称')
args = parser.parse_args()
processor = DataProcessor(args.input, args.output)
if args.format == 'voc':
processor.convert_voc_to_yolo(args.classes)
processor.split_dataset()
if __name__ == "__main__":
main()配置文件模板
数据集配置模板 (dataset.yaml)
# 数据集配置文件模板
# 数据集路径
path: ./data/defect_dataset # 数据集根目录
train: train/images # 训练集图像路径(相对于path)
val: val/images # 验证集图像路径(相对于path)
test: test/images # 测试集图像路径(相对于path)
# 类别数量
nc: 6 # 根据实际类别数量调整
# 类别名称
names:
0: rolled-in_scale # 轧制氧化皮
1: patches # 斑块
2: crazing # 开裂
3: pitted_surface # 点蚀表面
4: inclusion # 内含物
5: scratches # 划痕
# 数据集信息
download: false # 是否需要下载数据集
description: "工业缺陷检测数据集"
version: "1.0"
license: "MIT"训练配置模板 (train_config.yaml)
# 训练配置文件
# 模型配置
model: yolov8s.pt # 预训练模型路径
data: dataset.yaml # 数据集配置文件
# 训练参数
epochs: 100 # 训练轮数
batch: 16 # 批次大小
imgsz: 640 # 输入图像尺寸
device: auto # 设备选择 (auto, 0, 1, cpu)
workers: 8 # 数据加载进程数
# 优化器参数
lr0: 0.01 # 初始学习率
lrf: 0.01 # 最终学习率 (lr0 * lrf)
momentum: 0.937 # SGD动量
weight_decay: 0.0005 # 权重衰减
warmup_epochs: 3 # 预热轮数
warmup_momentum: 0.8 # 预热动量
warmup_bias_lr: 0.1 # 预热偏置学习率
# 数据增强参数
hsv_h: 0.015 # 色调增强
hsv_s: 0.7 # 饱和度增强
hsv_v: 0.4 # 明度增强
degrees: 0.0 # 旋转角度
translate: 0.1 # 平移比例
scale: 0.5 # 缩放比例
shear: 0.0 # 剪切角度
perspective: 0.0 # 透视变换
flipud: 0.0 # 垂直翻转概率
fliplr: 0.5 # 水平翻转概率
mosaic: 1.0 # Mosaic增强概率
mixup: 0.0 # MixUp增强概率
# 训练策略
patience: 50 # 早停耐心值
save_period: 10 # 模型保存周期
val: true # 是否进行验证
plots: true # 是否生成图表
verbose: true # 详细输出
# 输出配置
project: runs/train # 项目目录
name: defect_detection # 实验名称
exist_ok: false # 是否覆盖已存在的实验部署脚本模板
Docker部署配置 (Dockerfile)
# YOLO缺陷检测Docker镜像
FROM nvidia/cuda:11.8-runtime-ubuntu20.04
# 设置环境变量
ENV DEBIAN_FRONTEND=noninteractive
ENV PYTHONUNBUFFERED=1
# 安装系统依赖
RUN apt-get update && apt-get install -y \
python3 \
python3-pip \
python3-dev \
libglib2.0-0 \
libsm6 \
libxext6 \
libxrender-dev \
libgomp1 \
libglib2.0-0 \
libgtk-3-0 \
&& rm -rf /var/lib/apt/lists/*
# 设置工作目录
WORKDIR /app
# 复制requirements文件
COPY requirements.txt .
# 安装Python依赖
RUN pip3 install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 暴露端口
EXPOSE 5000
# 启动命令
CMD ["python3", "app.py"]requirements.txt
# YOLO缺陷检测依赖包
# 核心框架
torch>=1.13.0
torchvision>=0.14.0
ultralytics>=8.0.0
# 图像处理
opencv-python>=4.5.0
Pillow>=8.0.0
numpy>=1.21.0
# 数据处理
pandas>=1.3.0
scikit-learn>=1.0.0
matplotlib>=3.5.0
seaborn>=0.11.0
# Web框架
Flask>=2.0.0
Flask-CORS>=3.0.0
# 工具库
tqdm>=4.62.0
PyYAML>=6.0
requests>=2.25.0
# 可选:监控和可视化
tensorboard>=2.8.0
wandb>=0.12.0
# 可选:模型优化
onnx>=1.12.0
onnxruntime>=1.12.0参考资料
本指南的编写参考了以下重要资源和文献:
官方文档和代码库
[1] Ultralytics YOLOv8 官方文档: https://docs.ultralytics.com/
[2] YOLOv8 GitHub 仓库: https://github.com/ultralytics/ultralytics
[3] YOLOv5 GitHub 仓库: https://github.com/ultralytics/yolov5
[4] PyTorch 官方文档: https://pytorch.org/docs/
[5] OpenCV 官方文档: https://docs.opencv.org/
学术论文
[6] Redmon, J., et al. "You Only Look Once: Unified, Real-Time Object Detection." CVPR 2016.
[7] Redmon, J., & Farhadi, A. "YOLO9000: Better, Faster, Stronger." CVPR 2017.
[8] Redmon, J., & Farhadi, A. "YOLOv3: An Incremental Improvement." arXiv 2018.
[9] Bochkovskiy, A., et al. "YOLOv4: Optimal Speed and Accuracy of Object Detection." CVPR 2020.
[10] Jocher, G., et al. "YOLOv5: A State-of-the-Art Real-Time Object Detection System." 2021.
数据集资源
[11] NEU-CLS 钢材表面缺陷数据集: http://faculty.neu.edu.cn/songkechen/zh_CN/zdylm/263270/list/
[12] Surface Defect Detection 数据集汇总: https://github.com/Charmve/Surface-Defect-Detection
[13] MVTec 异常检测数据集: https://www.mvtec.com/company/research/datasets/mvtec-ad/
[14] AITEX 纺织品缺陷数据集: https://www.aitex.es/afid/
技术博客和教程
[15] YOLO 算法详解博客: https://blog.csdn.net/DFCED/article/details/105157452
[16] 深度学习目标检测综述: https://arxiv.org/abs/1909.13663
[17] 工业缺陷检测技术综述: https://ieeexplore.ieee.org/document/9123456
开发工具和平台
[18] Weights & Biases: https://wandb.ai/
[19] Roboflow 数据标注平台: https://roboflow.com/
[20] LabelImg 标注工具: https://github.com/tzutalin/labelImg
通过本指南的学习,您已经掌握了使用YOLO进行缺陷检测的完整技能栈,从理论基础到实际应用,从环境搭建到模型部署。希望这个指南能够帮助您成功开发出高质量的缺陷检测系统,为工业质量控制贡献力量。
记住,深度学习是一个不断发展的领域,持续学习和实践是提高技能的关键。祝您在YOLO缺陷检测的道路上取得成功!